Retrieval methods in RAG - Haystack
Retrieval Augmented Generation (RAG) is a model architecture for tasks requiring information retrieval from large corpora combined with generative models to fulfill a user information need. It’s typically used for question-answering, fact-checking, summarization, and information discovery.
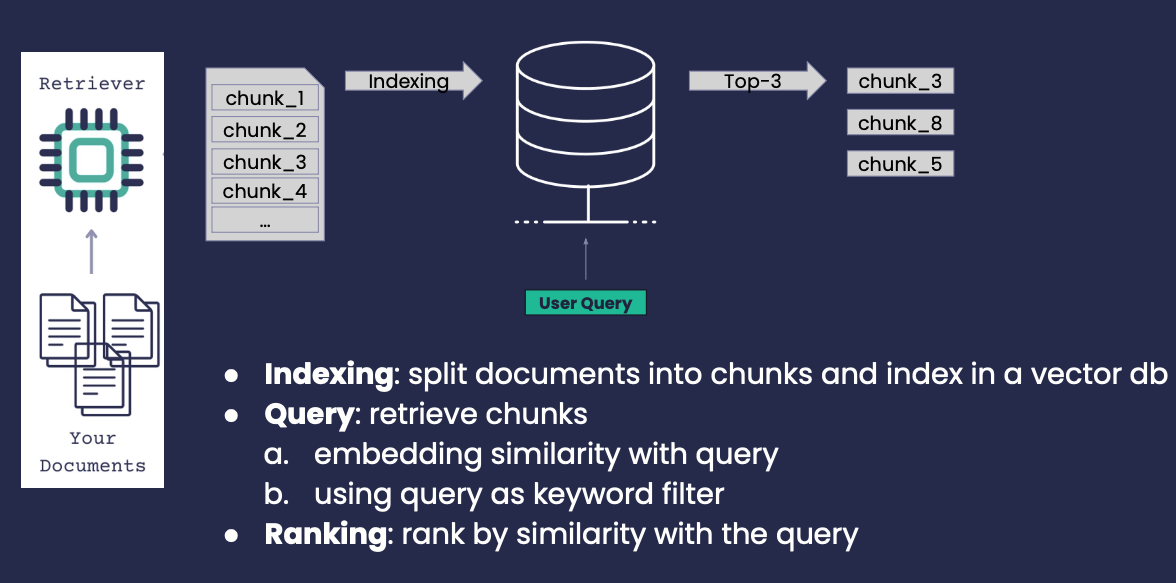
A Package for Machine Learning Evaluation Reporting
When working on machine learning projects, evaluating a model’s performance is a critical step. The ML-Report-Kit is a Python package that simplifies this process by automating the generation of evaluation metrics and reports. In this post, we’ll take a closer look at what ML-Report-Kit offers and how you can use it effectively.
Improving RAG Retrieval with Auto-Merging
For most RAG applications, where we first have to retrieve the most relevant context, we end up having to split up documents first, and index those smaller splits of documents. Reasons for this range from needing to retrieve only relevant sections of larger bits of documents to the simple fact that (although they’re improving massively) LLMs simply don’t have infinite context lengths.
Benchmarking Haystack Pipelines for Optimal Performance
In this article, we will show you how to use Haystack to evaluate the performance of a RAG pipeline. Note that the code in this article is meant to be illustrative and may not run as is; if you want to run the code, please refer to the python script.

Extract Metadata from Queries to Improve Retrieval
In Retrieval-Augmented Generation (RAG) applications, the retrieval step, which provides relevant context to your large language model (LLM), is vital for generating high-quality responses. There are possible ways of improving retrieval and metadata filtering is one of the easiest ways. Metadata filtering, the approach of limiting the search space based on some concrete metadata, can really enhance the quality of the retrieved documents.

Incorporate HyDE into Haystack RAG pipelines
Hypothetical Document Embeddings (HyDE) is a technique proposed in the paper “Precise Zero-Shot Dense Retrieval without Relevance Labels” which improves retrieval by generating “fake” hypothetical documents based on a given query, and then uses those “fake” documents embeddings to retrieve similar documents from the same embedding space. In this article, we will see how to implement and incorporate it into Haystack by creating a custom component that implements HyDE.

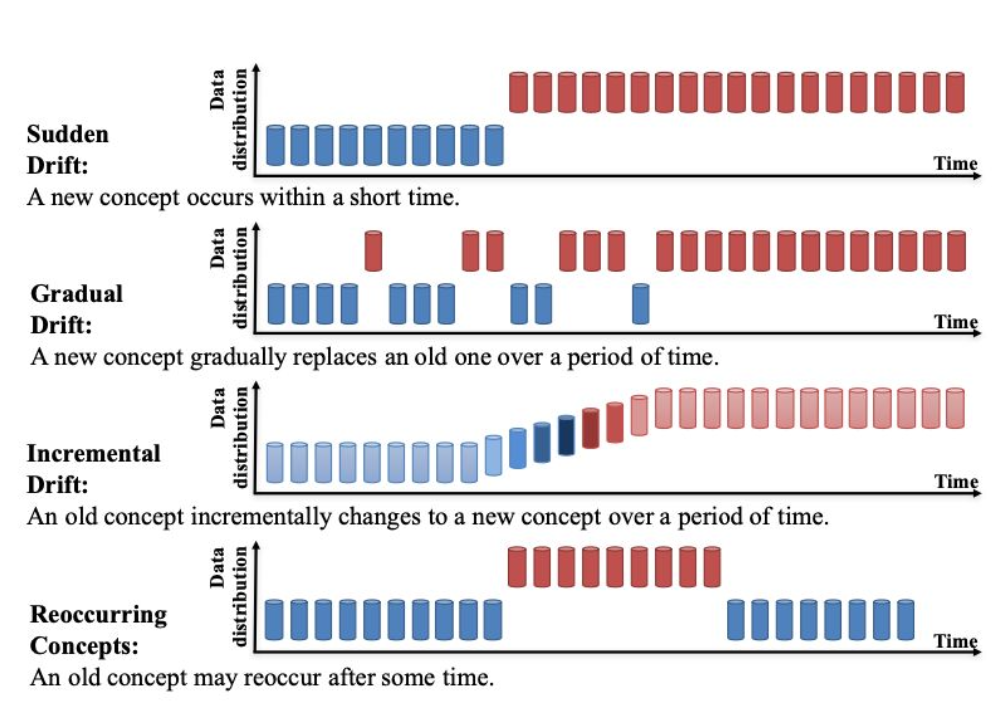
Semantic Drift in Machine Learning
Machine Learning models are static artefacts based on historical data, which start consuming “real-world” data when deployed into production. Real-world data might not reflect the historical training data and test data; the progressive changes between training data and “real-world” are called drift and it can be one of the reasons model accuracy decreases over time.
Sentence Transformer Fine-Tuning - SetFit
Sentence Transformers Fine-Tunning (SetFit) is a technique to mitigate the problem of a few annotated samples by fine-tuning a pre-trained sentence-transformers model on a small number of text pairs in a contrastive learning manner. The resulting model is then used to generate rich text embeddings, which are then used to train a classification head, resulting in a final classifier fine-tuned to the specific dataset.
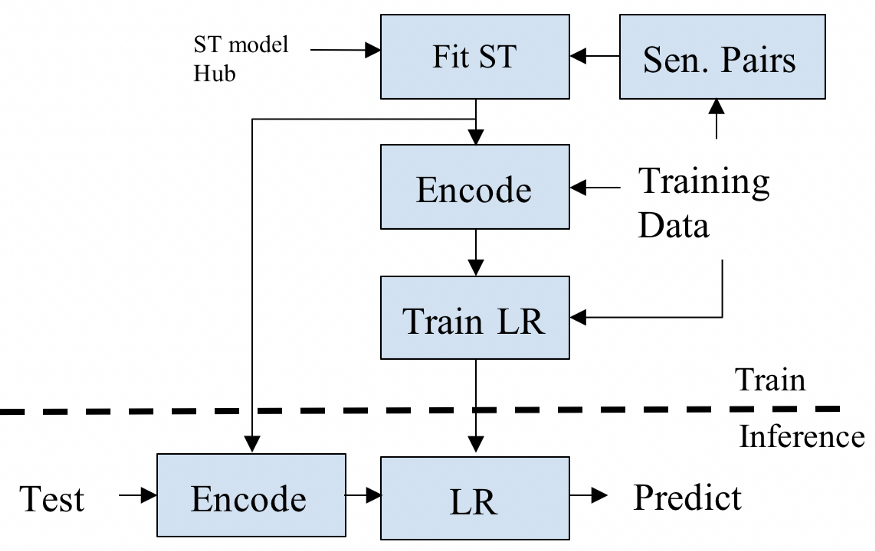
Sentence Transformers
The sentence-transformers proposed in Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks is an effective and efficient way to train a neural network such that it represents good embeddings for a sentence or paragraph based on the Transformer architecture. In this post I review mechanism to train such embeddings presented in the paper.
Generative AI with Large Language Models
I’ve completed the course and recommend it to anyone interested in delving into some of the intricacies of Transformer architecture and Large Language Models. The course covered a wide range of topics, starting with a quick introduction to the Transformer architecture and dwelling into fine-tuning LLMs and also exploring chain-of-thought prompting augmentation techniques to overcome knowledge limitations. This post contains my notes taken during the course and concepts learned.
Support and Opposition Relationships in Political News Headlines
I was awarded the 2nd place in the Arquivo.pt Awards 2021 for the Politiquices project. The project aimed at extracting supportive and opposing relationships between political personalities from news headlines archived by Arquivo.PT, and associating the personalities with their identifier on Wikidata, thus resulting in a semantic graph. I published recently the results of this project in Portuguese on Linguamatica v. 15 n. 1. The content of this blog post is the same as in the paper but translated to English.
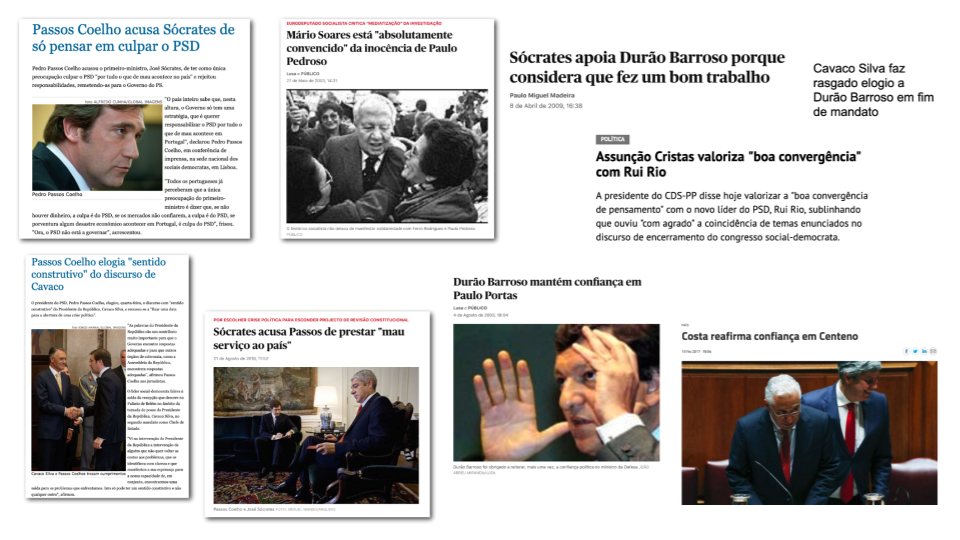
Text Summarisation Techniques
Text summarisation resumes the information contained in a text, into a shorter version, still capturing the original semantics. This can be achieved by selecting representative words or phrases from the original text and combining them to make a summary (extractive), or by writing a summary as a human would do, by generating a textual summary of the main content in the original text (abstractive). This post quickly reviews some of the recent works on NLP Text summarisation using both approaches.
Machine Learning in Production
I enrolled and successfully completed the Machine Learning Engineering for Production - Specialisation from Coursera. This blog post aims to give a review of the course and the topics discussed, it’s mostly based on the notes I took during the video lectures. The course covers a wide range of topics and it can feel overwhelming, which is another reason for me to write these review notes.

Natural Language Processing Books
Learning about Natural Language Processing is a continuous task, which appears not to have an end, but, there is always a starting point where one learns the problem definitions and the common algorithms to solve them. In this post, I will share some of the books that I used during my path to learn about Natural Language Processing. I think most of these books are a good starting point to learn about Natural Language Processing and how to apply Machine learning to NLP tasks. Most of these books and tutorials are nice to have around so that you can quickly clarify any doubts or review how a certain algorithm or technique works. I personally like to have them at hand :)

A collection of examples of SPARQL queries to Wikidata
A collection of several SPARQL queries to WikiData. Those are queries over different domains or topics that I’ve used for different goals. I’ve just decided to make them here public so that I can quickly refer to and reused them in other queries.

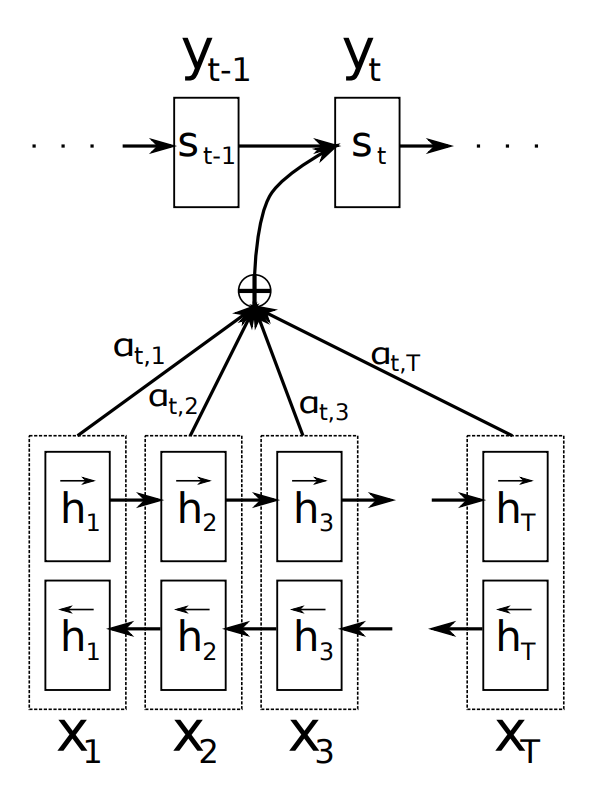
The Attention Mechanism in Natural Language Processing
The Attention mechanism is now an established technique in many NLP tasks. I’ve heard about it often but wanted to go a bit more deeply and understand the details. In this first blog post - since I plan to publish a few more blog posts regarding the attention subject - I make an introduction by focusing on the first proposal of attention mechanism, as applied to the task of neural machine translation.
Portuguese Word Embeddings
While working on some projects of mine I come to a point where I needed pre-trained word embeddings for Portuguese. I could have trained some on my own on some corpora but I did not want to spend time on cleaning and running the training, so instead I searched the web for collections of word vectors for Portuguese, here’s a compiled list of what I’ve found.

KOVENS'19 - The German-focused NLP Conference
KONVENS is an annual conference, which gathers together the computer scientist and computational linguist community working with the German language.

Language Models and Contextualised Word Embeddings
Since the work of Mikolov et al., 2013 was published and the software package word2vec was made public available a new era in NLP started on which word embeddings, also referred to as word vectors, play a crucial role. Word embeddings can capture many different properties of a word and become the de-facto standard to replace feature engineering in NLP tasks.

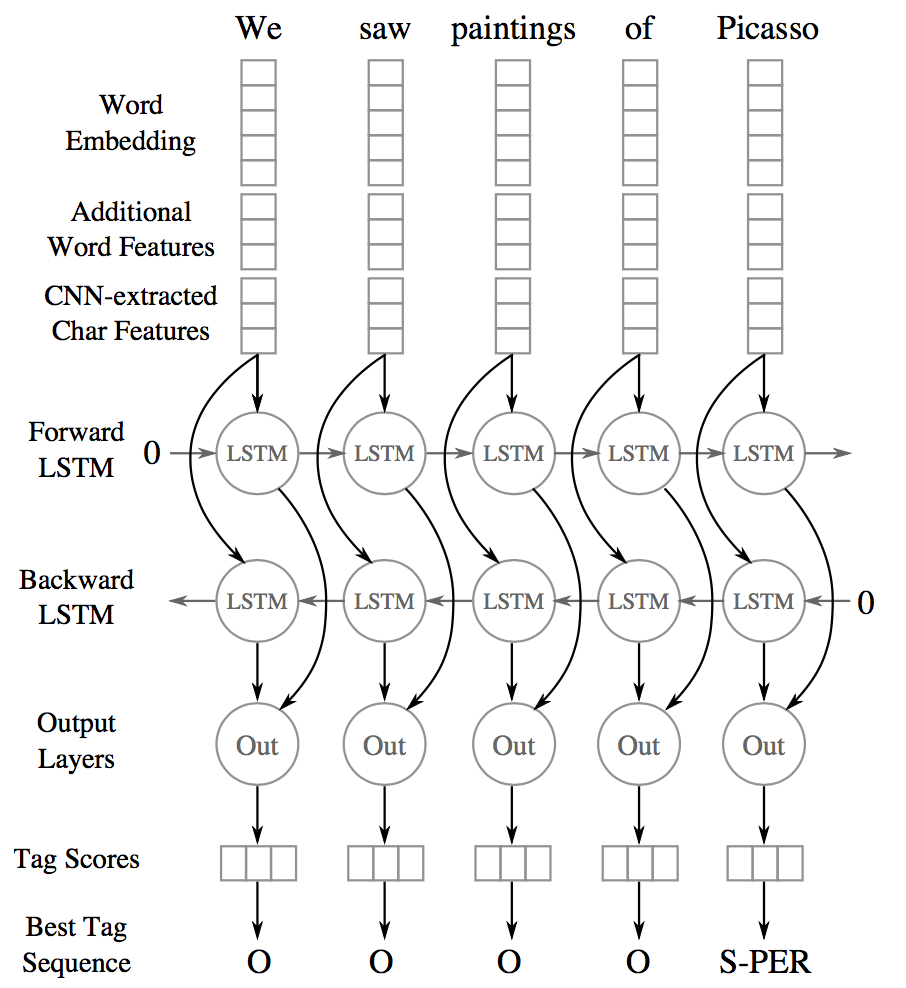
Named-Entity Recognition based on Neural Networks
Recently (i.e., at the time of this writing since 2015~2016 onwards) new methods to perform sequence labelling tasks based on neural networks started to be proposed/published, I will try in this blog post to do a quick recap of some of these new methods, understanding their architectures and pointing out what each technique brought new or different to the already knew methods.
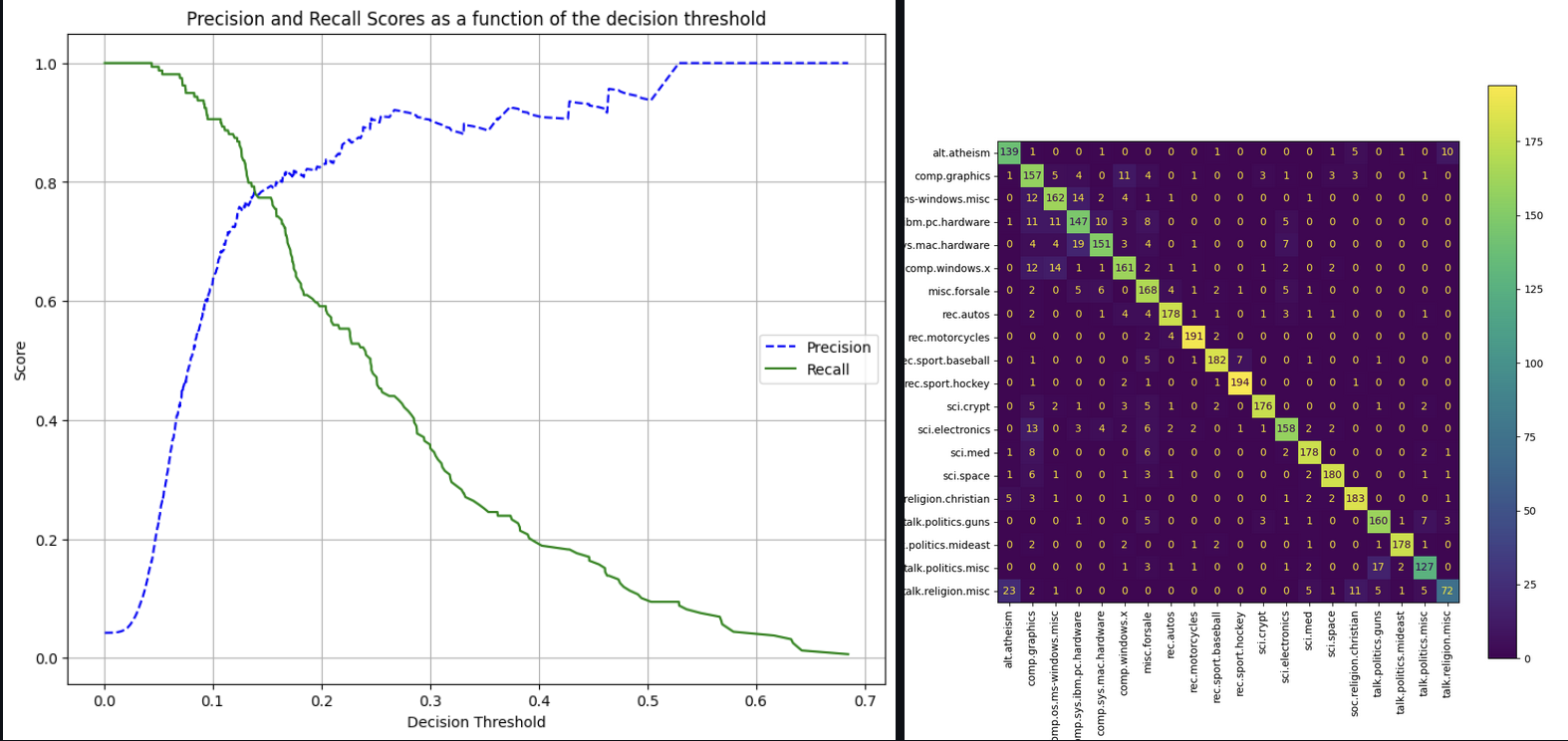
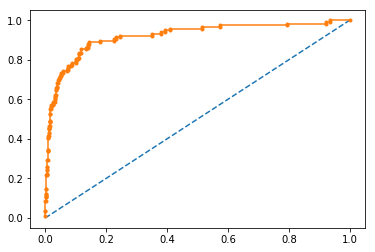
Evaluation Metrics, ROC-Curves and imbalanced datasets
I wrote this blog post with the intention to review and compare some evaluation metrics typically used for classification tasks, and how they should be used depending on the dataset. I also show how one can tune the probability thresholds for particular metrics.
Named-Entity evaluation metrics based on entity-level
When you train a NER system the most typical evaluation method is to measure precision, recall and f1-score at a token level. These metrics are indeed useful to tune a NER system. But when using the predicted named-entities for downstream tasks, it is more useful to evaluate with metrics at a full named-entity level. In this post I will go through some metrics that go beyond simple token-level performance.

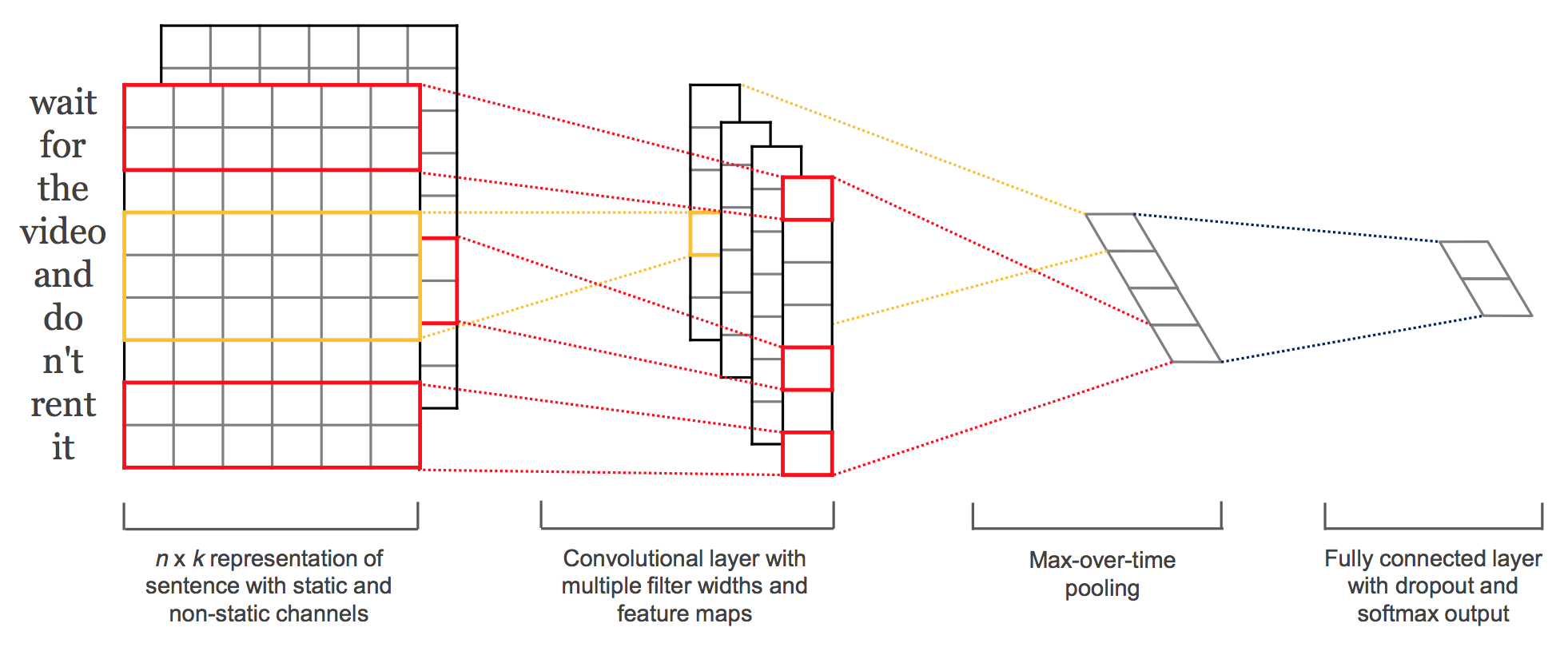
Convolutional Neural Networks for Text Classification
Convolutional Neural Networks (ConvNets) have in the past years shown break-through results in some NLP tasks, one particular task is sentence classification, i.e., classifying short phrases (i.e., around 20~50 tokens), into a set of pre-defined categories. In this post I will explain how ConvNets can be applied to classifying short-sentences and how to easily implemented them in Keras.
Applying scikit-learn TfidfVectorizer on tokenized text
Sometimes your tokenization process is so complex that cannot be captured by a simple regular expression that you can pass to the scikit-learn TfidfVectorizer. Instead you just want to pass a list of tokens, resulting of a tokenization process, to initialize a TfidfVectorizer object.

Hyperparameter optimization across multiple models in scikit-learn
I found myself, from time to time, always bumping into a piece of code (written by someone else) to perform grid search across different models in scikit-learn and always adapting it to suit my needs, and fixing it, since it contained some already deprecated calls. I finally decided to post it here in my blog, so I can quickly find it and also to share it with whoever needs it.
StanfordNER - training a new model and deploying a web service
Stanford NER is a named-entity recognizer based on linear chain Conditional Random Field (CRF) sequence models. This post details some of the experiments I’ve done with it, using a corpus to train a Named-Entity Recognizer: the features I’ve explored (some undocumented), how to setup a web service exposing the trained model and how to call it from a python script.

Conditional Random Fields for Sequence Prediction
This is the third and (maybe) the last part of a series of posts about sequential supervised learning applied to NLP. In this post I will talk about Conditional Random Fields (CRF), explain what was the main motivation behind the proposal of this model, and make a final comparison between Hidden Markov Models (HMM), Maximum Entropy Markov Models (MEMM) and CRF for sequence prediction.
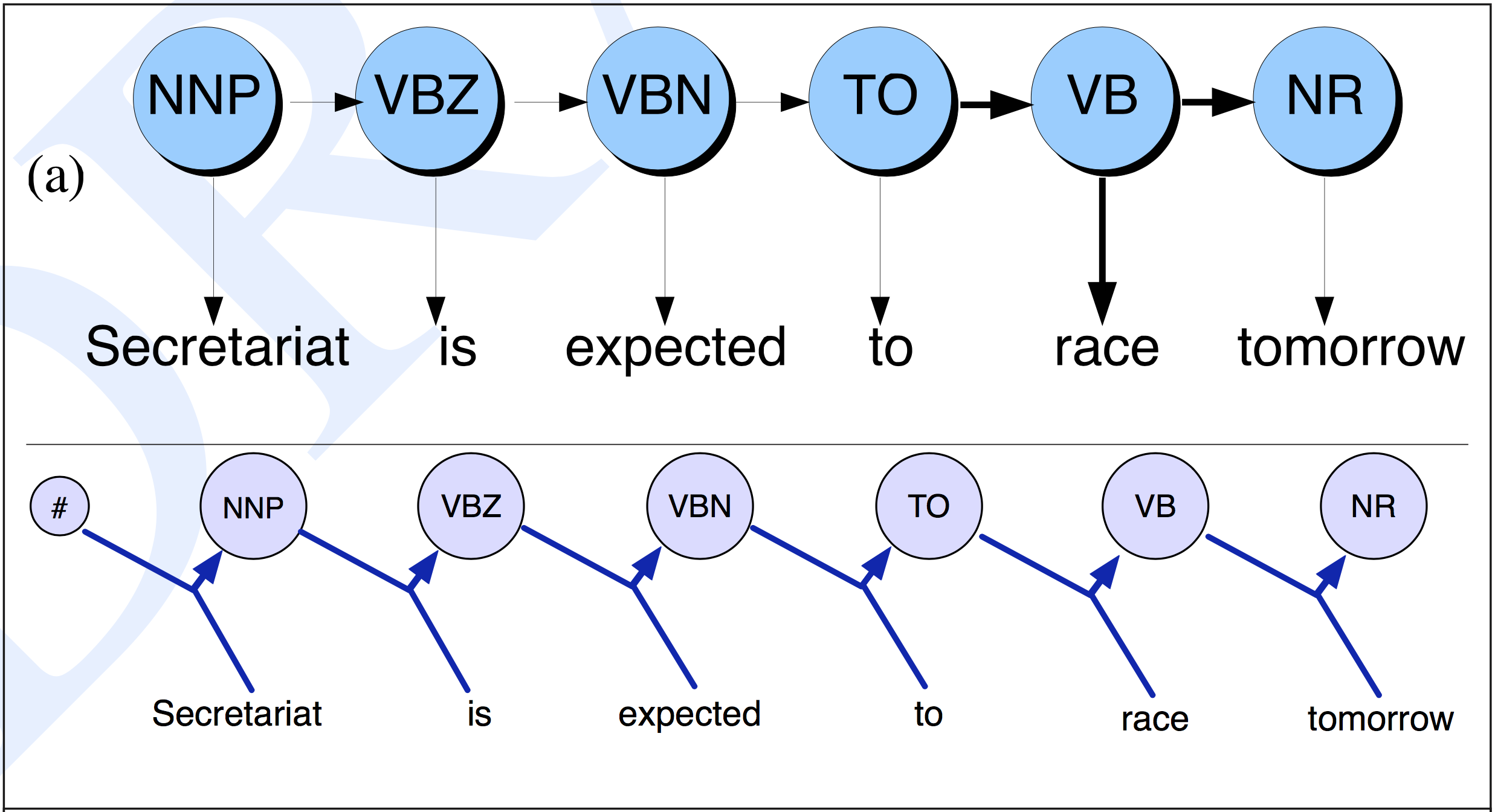
Maximum Entropy Markov Models and Logistic Regression
This is the second part of a series of posts about sequential supervised learning applied to NLP. It can be seen as a follow-up to the previous post, where I tried to explain the relationship between HMM and Naive Bayes. In this post I will try to explain how to build a sequence classifier based on a Logistic Regression classifier, i.e., using a discriminative approach.
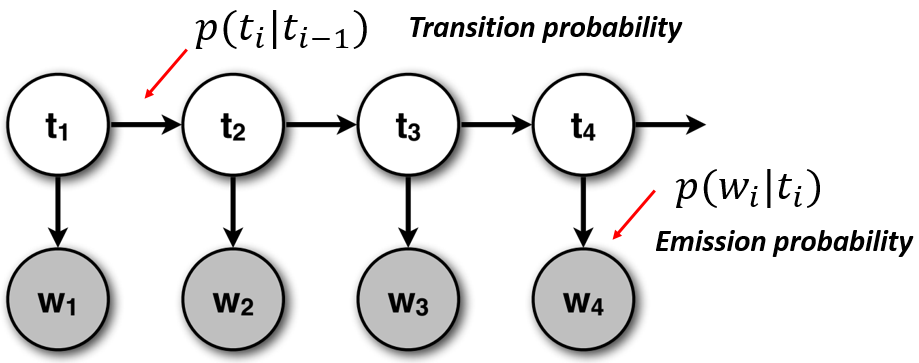
Hidden Markov Model and Naive Bayes relationship
This is the first post, of a series of posts, about sequential supervised learning applied to Natural Language Processing. In this first post I will write about the classical algorithm for sequence learning, the Hidden Markov Model (HMM), and explain how it’s related to the Naive Bayes Model and its limitations.
Google's SyntaxNet - HTTP API for Portuguese
In a previous post I explained how to load the syntactic and morphological information given by SyntaxNet into NLTK structures by parsing the standard output. Although useful this does not scale when one wants to process thousands of sentences, but finally, I’ve found a Docker image to set up SyntaxNet as a web-service.
PyData Berlin 2017
The PyData Berlin conference took place at the first weekend of July, at the HTW. Full 3 days of many interesting subjects including Natural Language Processing, Machine Learning, Data Visualisation, etc. I was happy to have my talk proposal accepted and had the opportunity to present work done during my PhD on Semantic Relationship extraction.

Open Information Extraction in Portuguese
In this post I will present one of the first proposed Open Information Extraction systems, which is very simple and effective, relying only on part-of-speech tags. I also implement it and apply it to Portuguese news articles.

Document Classification
Classifying a document into a pre-defined category is a common problem, for instance, classifying an email as spam or not spam. In this case there is an instance to be classified into one of two possible classes, i.e. binary classification.
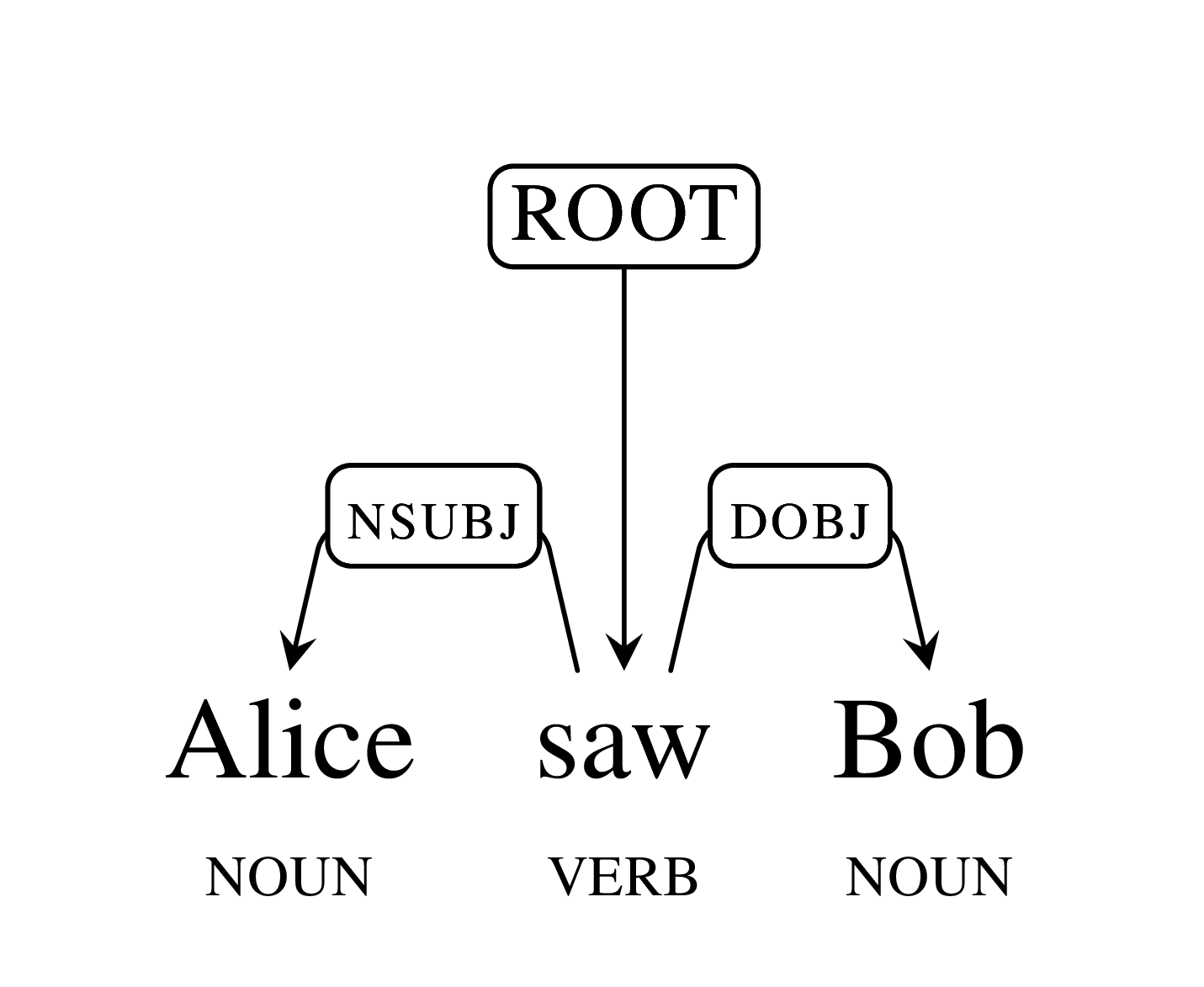
Google's SyntaxNet in Python NLTK
In May 2016 Google released SyntaxNet, a syntactic parser whose performance beat previously proposed approaches.
