Support and Opposition Relationships in Political News Headlines
I was awarded the 2nd place in the Arquivo.pt Awards 2021 for the Politiquices project. The project aimed at extracting supportive and opposing relationships between political personalities from news headlines archived by Arquivo.PT, and associating the personalities with their identifier on Wikidata, thus resulting in a semantic graph. I published recently the results of this project in Portuguese on Linguamatica v. 15 n. 1. The content of this blog post is the same as in the paper but translated to English.
The datasets resulted from this work are publicly available
- Semantic Graph as TTL file
- JSONL containing the annotated headlines
- Annotated headlines 4-fold cross validation
@article{Soares Batista_2023,
title={Extracção de Relações de Apoio e Oposição em Títulos de Notícias de Política em Português},
volume={15},
url={https://linguamatica.com/index.php/linguamatica/article/view/386},
DOI={10.21814/lm.15.1.386},
number={1},
journal = {Linguam{\'a}tica},
author={Soares Batista, David},
year={2023},
month={Jul.},
pages={91-101}
}

Introduction
News headlines related to politics or politicians often report interactions involving two or more political personalities. Many of these interactions correspond to relationships of support or opposition from one personality to another, for example:
-
“Marques Mendes criticises Rui Rio's strategy”
-
“Catarina Martins calls for the resignation of Governor Carlos Costa"
-
“Sócrates went to the grassroots to call for a vote for Soares"
Analysing a large number of these types of relationships over time allows for various studies, for example: finding out which are the major communities of support or opposition depending on the governments in power, or finding the major alliances and oppositions and their dynamics.
You can also explore an individual personality over time, for example by comparing the relationships of support or opposition before taking office in a particular public position with the relationships after taking office, or to see which relationships of support have suddenly emerged.
A database collating news stories expressing relationships of support or opposition between political personalities can be used to quickly assemble a collection of news stories containing or involving specific personalities and political parties, for example, to assist in an investigative journalism task.
Having an automatic method for extracting relationships and being able to apply it to a collection of data covering long periods of time would make it possible to realise the examples described above.
In this paper we present a method for extracting relationships of support or opposition between political personalities and describe the results of applying it to a news collection covering a period of around 25 years.
During the relationship extraction process, we linked the political personalities involved with their Wikidata identifier (Malyshev et al., 2018) 1, thus enriching the relationship with information associated with the personality (e.g. political affiliation, public offices held, legislatures, family relationships, etc.).
All the relationships extracted are represented in the form of semantic triples following the Resource Description Framework (RDF) standard (Schreiber & Raimond, 2014) 2. The political personalities involved, represented by their Wikidata identifier, are linked through a relationship of opposition or support represented by the news item that supports the relationship. This structure thus gives rise to a semantic graph, making it possible to formulate SPARQL queries (Prud’hommeaux et al., 2013) 3 involving the Wikidata information associated with each personality and the relationships extracted from the news headlines, for example:
-
List all the news items where personality X opposes personality Y
-
List the members of a given party who supported a specific personality
-
List the members of a particular party supported/opposed by members of another party
-
List personalities who are linked through a family relationship and an opposition/support relationship
-
List personalities who are part of the same government and are involved in an opposition/support relationship
The main contributions of this work are:
-
a semantic graph linking political personalities represented on Wikidata through an opposition or support relationship supported by a news item
-
an annotated dataset used to train classifiers for extracting sentiment-driven relations from news headlines, and also to link the personalities mentioned to Wikidata
-
a web interface to explore the semantic graph
This article is organised as follows:
- in Section 2 we refer to related work,
- in Section 3 we describe the knowledge base used to support the linking of personalities to Wikidata
- in Section 4 refers to and describes the news sources used.
- in Section 5 we detail the annotated dataset
- in Section 6 the supervised learning classifiers developed
- in Section 7 we describe the RDF triple extraction process and the construction of the semantic graph.
- in Section 8 we summarise the conclusions of this work and present some ideas for future work.
Related Work
Sentiment analysis, in the context of Natural Language Processing, has mostly been studied in content generated on social networks (Zimbra et al., 2018) 4 or in the evaluation of products or services (Pontiki et al., 2016) 5. In these areas, the author of the text and the target of the opinion are explicit. In the context of analysing political news, where there is often sentiment expressed between political actors in the form of support or opposition relationships (Balahur et al., 2009 6, 2010 7), sentiment analysis approaches to products or services do not apply, as the direction of the sentiment relationship has to be considered.
In this section we describe resources similar to those we have produced in this work, which we have made public, and approaches to the task of extracting targeted sentiment in political news text.
Resources and annotated datasets
Sarmento et al., (2009) 8 propose a method for the automatic creation of a corpus for the detection of positive or negative sentiment towards a political personality, and apply the method to comments on online newspaper reports. In this resource, the source of the sentiment is assumed to be the commentator.
Moreira et al., (2013) 9 provide an ontology describing political actors, their positions and affiliated political parties, using official sources of information and information gathered from the web to add alternative names to the personalities present in the ontology.
de Arruda et al. (2015) 10 created a corpus of political news in Brazilian Portuguese, annotating each paragraph with the sentiment according to two dimensions: the political actor referred to by the paragraph, and the sentiment of that reference: positive, negative or neutral. The origin of the sentiment is left open in this resource. Baraniak & Sydow, (2021) 11 provide similar corpora, annotating the sentiment towards a political personality in newspaper texts on-line, for English and Polish.
Extracting Targeted Sentiment from News Text
Several authors have explored methods for extracting sentiment involving political actors. It should be noted that many of the works transform the task of detecting sentiment into a task of detecting a relationship between mentioned entities (Bassignana & Plank, 2022) 12.
Some explore these relationships in an international political context, i.e.: the actors are nations mentioned in political news text, and some of these relationships implicitly have a positive or negative sentiment. O’Connor et al. (2013) 13 propose an unsupervised model based on topic models and linguistic patterns to identify relationships, in an open-ended way, describing conflicts between nations referenced in English news articles.
Han et al. (2019) 14 also propose an unsupervised model to generate relationship descriptors for pairs of nations mentioned in English news articles. The proposed model extends the work of Iyyer et al. (2016) 15 by integrating linguistic information (i.e.: verbal predicates and common and proper nouns) in order to identify the context of the relations.
Liang et al. (2019) 16 defines the task of extracting guilt relations for English texts: given an article \(d\) and a set of entities \(E\), present in the article, detect if there is a guilt relation \((s,t)\), where \(s,t \in E\), when \(s\) blames \(t\) based on the article \(d\), and there$ are \(\lvert{E}\rvert \cdot (\lvert{E}\rvert - 1)\), possible guilt relations. To detect these relationships, the authors propose 3 models. The Entity Prior model extracts information about entities, trying to capture a prior about who is likely to blame whom without additional information. The Context model makes use of the context information of the sentence where two entities occur to determine the presence of a blame relationship. The Combined model combines the information from the two previous models into a single model. The authors applied this approach to a corpus with 998 news articles and about 3 entities per article, reporting a macro-average F1 of 0.70 with the Combined model.
Park et al. (2021) 17 proposes a structure of relations to detect sentiment and direction: given a sentence \(s\) referring to two entities \(p\) and \(q\), detect which sentiment relation between \(p\) and \(q\) out of five possible ones: neutral, \(p\) has a positive or negative opinion of \(q\), or \(q\) has a positive or negative opinion of \(p\). In their work, the authors use multiple models by transforming the sentiment extraction task into sub-tasks that answer yes/no questions for each of the 5 possible sentiments, then combining the various results into a final result. This approach is applied to English in a corpus created by the authors containing sentences from news articles containing at least two entities.The pairs of entities are annotated with one of the 5 possible sentiments. The authors report a macro-average F1 of 0.68.
Knowledge Base Construction
Given that the personalities involved in the relationships to be extracted are relevant political personalities, we started by building a knowledge base from Wikidata (Malyshev et al., 2018) 1.
By making SPARQL queries to the public endpoint we collected the identifier of all:
-
people who are or have been affiliated with a Portuguese political party
- Portuguese people born after 1935 whose profession is:
- judge
- economist
- lawyer
- civil servant
- politician
- businessman
- banker
- people who hold or have held at least one office from a list of previously selected Portuguese public offices (e.g.: minister, party leader, ambassador, etc.)
In addition to the results of these queries, we manually selected some identifiers of personalities not covered by the SPARQL queries defined above, many of them from an international political context, but who interact with Portuguese personalities.
We also added all the identifiers of political parties to which the personalities collected are affiliated. This process resulted in a total of 1,757 personalities and 37 political parties. It should be noted that some of the parties included are now defunct and/or from an international context.
For each of the identifiers of the personalities and parties, we downloaded the corresponding page from Wikidata using another public endpoint. For each political figure we selected: their Wikidata identifier, their most common name and alternative names, i.e. combinations of first names and surnames.
Based on these three fields, we created an index in ElasticSearch (Gormley & Tong, 2015) 18 using its default configuration, not making use of any extra functionality such as \(n\)-gram parsers.
Data Sources
The main source of news was the Portuguese web archive (Gomes et al., 2013) 19. Using the public search API we collected archived pages, restricting the results to occurrences of names gathered in Section 3 and 45 .pt domains associated with various sources of information such as:
- online newspaper
- websites of television
- radio stations websites
- content aggregator portals
A second news source was the CHAVE collection (Santos & Rocha, 2004 20, 200121), containing articles from the newspaper PÚBLICO published between 1994 and 1995. Finally, some articles not archived by arquivo.pt were also added, taken directly from the World, Politics and Society sections of the publico.pt website.
This process resulted in a collection of around 13.7 million article titles published between 1994 and 2022. Pre-processing was then applied in order to remove news items with: duplicate titles, titles with less than 4 words, and titles or URLs containing words that are part of a pre-defined list (e.g.: sports, celebrities, arts, cinema, etc.) that suggest a context other than politics. This pre-processing resulted in 1.3 million different titles, around 10 per cent of the data initially collected.
Dataset of Support and Opposition Political Relationships
In order to be able to train supervised learning classifiers to identify the relationships present in the news headlines, and to link the personalities with Wikidata, we manually annotated headlines with: the mentions of personalities, the identifiers in Wikidata and the relationship between the personalities mentioned.
We began by pre-processing all the headlines collected using the spaCy 3.0 software package 22, and the pt_core_news_lg-3.0.0 model to recognise named-entities of the PERSON type. For each recognised entity we tried to find its corresponding identifier in Wikidata by querying the index described in Section 3 and assuming that in the list of results the first is the correct identifier associated with the entity. We then selected the titles for annotation, including only titles referring to at least two personalities.
In the annotation process all the titles were loaded into the Argilla annotation tool, and using the graphical interface we selected titles to annotate.
For each title, we corrected the recognised entities and their Wikidata identifiers where necessary. We annotated the existing relationship: opposition or support, and its direction. When neither is the case, the relationship is noted as other.
Table 1 shows some examples of the annotated relationships. The annotation process was carried out by one single annotator. In the most ambiguous situations, for example, where the full information in the news text is needed to decide, the relationships have been annotated as other.
| Headline | Relationship | |
|---|---|---|
| Sá Fernandes accuses António Costa of defending corporate interests | Ent1-opposes-Ent2 | |
| Joana Mortágua: statements by Cavaco are “a series of nonsense” | Ent1-opposes-Ent2 | |
| Passos Coelho is accused of political immaturity by Santos Silva | Ent2-opposes-Ent1 | |
| Durão Barroso supports Paulo Portas as an “excellent minister” | Ent1-supports-Ent2 | |
| Armando Vara chosen by Guterres to coordinate local elections | Ent2-supports-Ent1 | |
| Manuel Alegre receives support from Jorge Sampaio | Ent2-supports-Ent1 | |
| Rui Tavares and Ana Drago elected in the LIVRE primaries | other | |
| Teresa Zambujo acknowledges Isaltino Morais’ victory | other | |
| CDS accuses Marcelo Rebelo de Sousa of jeopardising the relationship with Cavaco | other |
Table 1: Examples of headlines and the corresponding manually annotated relationships.
This process resulted in a dataset containing 3 324 annotated titles. For each title we annotated only two personalities and the relationship between them, even if the titles contain references to more than two personalities.
Table 2 characterises the data in terms of number of relationships and direction. Most titles contain an opposition or other relationship, and the vast majority of relationships have a direction from the first to the second entity, Ent1 → Ent2.
| Relação |
Ent1 → Ent2 |
Ent1 ← Ent2 |
Total |
|
|---|---|---|---|---|
| opposes | 1 155 | 102 | 1 257 | |
| supports | 717 | 44 | 761 | |
| other | - | - | 1,306 | |
| Total | 1,872 | 146 | 3,324 |
Table 2: Relationships by class and direction.
The ratio of oppositional relationships to supportive relationships is 1.6. This value is similar to the data for English provided by Park et al. (2021) 17, where this same ratio between the two classes is 1.8. In terms of class representativeness, aggregated by sentiment, the two datasets are also similar, with other being the most present class, followed by opposition and lastly support.
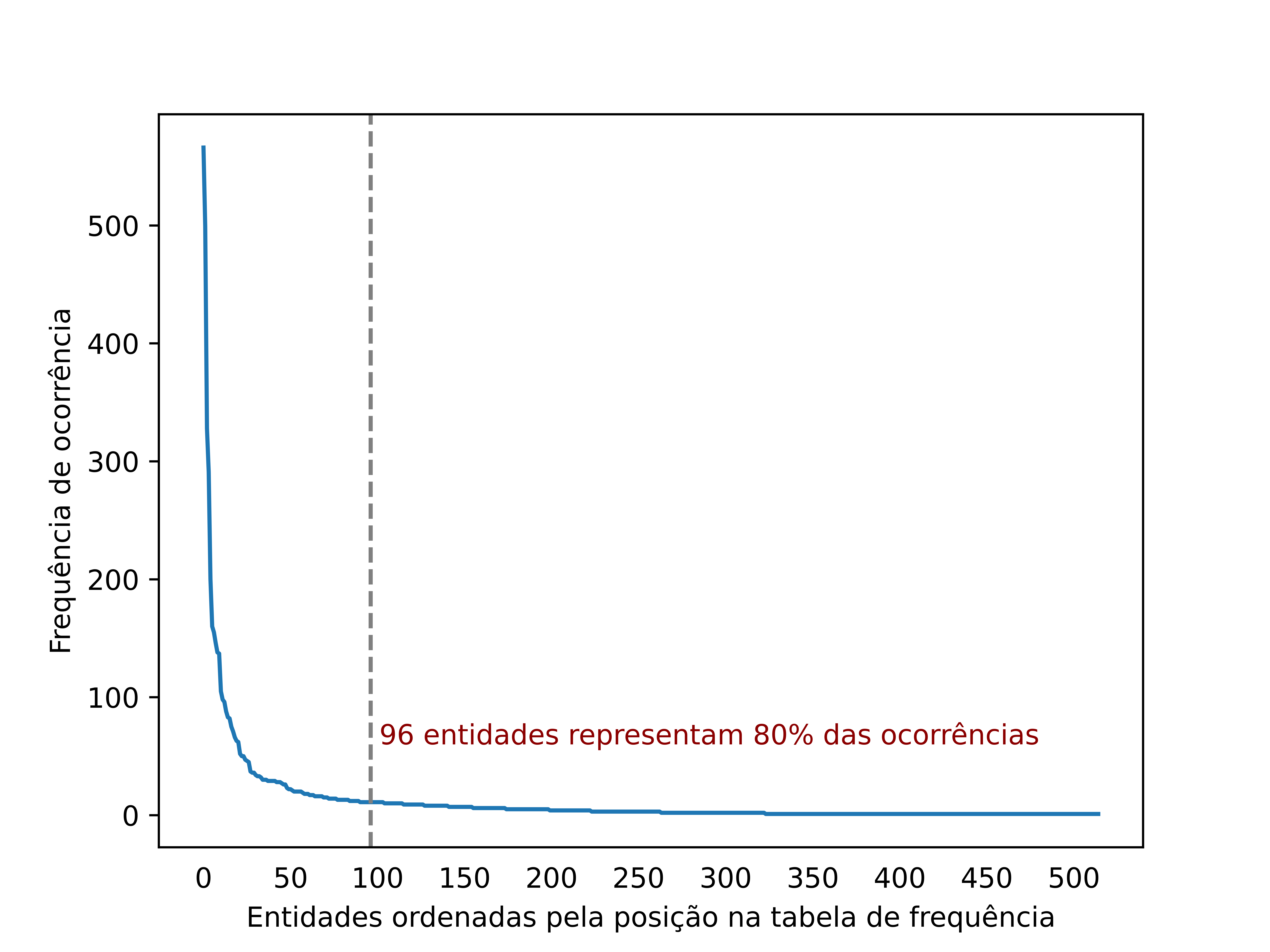
Of the 6 648 mentions of names of political personalities annotated, 515 are distinct and have an identifier on Wikidata. A total of 129 distinct entities, identified by aggregating the string that mentions them in the title, are not associated with an identifier because they are not present in Wikidata.
Analysing the frequency of occurrence of each entity shows that there are a small number of entities responsible for a large proportion of all entity occurrences in the annotated data. As shown in Figure 1 there is a small number of frequent entities, and a long list of infrequent entities, specifically, 96 distinct personalities, i,.e.: 19% of the personalities, are responsible for 80% of the mentions of personalities in the data. In terms of the number of words contained in the titles, excluding words that are part of the entities, there is a median of 8 words with a maximum of 22 and a minimum of 1.
This annotated dataset is online in JSON format as illustrated in below in Figure 2.
{"title": "Ana Gomes defende Durão Barroso",
"label": "ent1_supports_ent2",
"date": "2002-05-11 08:26:00",
"url": "http://www.publico.pt/141932",
"ent1": "Ana Gomes",
"ent2": "Durão Barroso",
"ent1_id": "Q2844986'",
"ent2_id": "Q15849"}
Figure 2: Example of one annotated sample in JSON.
Relationship Extraction Process
The process of extracting RDF triples from news headlines involves 4 sub-processes:
-
recognising entity mentions of type
PERSON -
linking entities with an identifier in Wikidata
-
classifying the type of relationship
-
classifying the direction of the relationship
Named-Entity Recognition
The recognition of entities mentioned is based on a hybrid method, combining rules with a supervised model.
Using the EntityRuler component of spaCy 3.0, we define a series of of rules combining patterns based on the names of all the personalities from the knowledge base described in Section 3.
To detect entities of type PERSON this classifier applies first the rules and then the supervised model for Portuguese model. In situations of disagreement between the two approaches, the entities marked with rules are prioritised. Table 3 shows the performance for the 3 approaches on the annotated dataset.
| Approach |
Precision |
Recall |
F-1 | |
|---|---|---|---|---|
| Rules | 0,99 | 0,42 | 0,59 | |
| Model | 0,97 | 0,91 | 0,94 | |
| Rules+Model | 0,97 | 0,92 | 0,94 |
Table 3: Precision, Recall and F1 for the NER component combining rules and a supervised model.
Entity Linking over Wikidata
The algorithm for associating personalities with identifiers on Wikidata has two phases. In the first phase, the algorithm only tries to use the title of the news item; if this process fails, it then tries to use possible references to the personalities in the text of the news item.
The algorithm first interrogates the knowledge base (KB) using the reference to the personality in the headline, thus generating a list of candidates for a given personality. If the list contains only one candidate and the Jaro (1998) 23 similarity to the personality mentioned in the headline is at least 0.8, that candidate is selected. If there is more than one candidate, the algorithm filters out only those with a similarity of 1.0 and if there is only one, that is the candidate selected. In any other case, no candidate is returned.
Algorithm 1 describes the procedure that uses only the headline.
def title_only(ent, candidates):
if len(candidates) == 1:
if jaro(ent, candidates[0]) >= 0.8:
return candidates[0]
else:
filtered = exact(ent, candidates)
if len(filtered) == 1:
return candidates[0]
return None
If no candidates are generated in the first phase or none are selected from the list of candidates, the algorithm tries to expand the entities mentioned in the headline based on the news text, exploiting a pattern: a personality mentioned in the headline by a short version of their name (e.g. just their surname) is usually referred to in the news text by a fuller name.
The algorithm identifies all the people mentioned in the news text, using the component described in Section 6.1, and selects only those that have at least one name in common with the name of the personality mentioned in the headline, thus generating an expanded entity, and assuming that it corresponds to the same entity mentioned in the headline.
If the process results in only one expanded entity and there is a similarity of 1.0 with one of the candidates previously selected from the KB, that candidate is chosen. Otherwise, the expanded entity is used to query the KB and collect a new list of candidates. If there is only one candidate on this list and its similarity is at least 0.8 to the expanded entity, that candidate is chosen. If there is more than one candidate and only one has a similarity of 1.0 to the expanded entity, that one is chosen.
def article_text(expanded, candidates):
if len(expanded) == 1:
filtered = exact(expanded[0], candidates)
if len(filtered) == 1:
return filtered[0]
x_candidates = get_candidates(expanded)
if len(x_candidates) == 1:
if jaro(expanded, x_candidates[0])>=0.8:
return x_candidates[0]
filtered = exact(expanded, x_candidates)
if len(filtered) == 1:
return matches[0]
if len(expanded) > 1:
filtered = []
for e in expanded:
exact_candidates = exact(e, candidates)
for c in exact_candidates:
filtered.append(c)
if len(filtered) == 1:
return filtered[0]
return None
If the expansion process results in several expanded entities, we filter out candidates from the KB with a similarity of 1.0 to the expanded entity, and if there is only one, that candidate is chosen. In any other case not described here, no candidate is selected.
Algorithm 2 describes this procedure using the text of the news item.
The results of this approach on the annotated dataset are described in Table 3. The incorrect classification corresponds to personalities who were not associated with the correct identifier in Wikidata, not disambiguated for those for whom the algorithm was unable to select a unique identifier from all the candidates or the KB did not return any results.
In Table 3 two evaluations are reported, the first column describes the results for the base algorithm, without mappings. The second column considers the ambiguity that a reference may have in terms of the personalities it represents. For example, in the annotated data, all mentions of Cavaco correspond to the personality Cavaco Silva, based on this the algorithm maps all references to Cavaco to Cavaco Silva. Similarly, all mentions of Marques Mendes correspond to the personality Luís Marques Mendes. By using these mappings we reduce the number of entities for which the algorithm cannot find an identifier.
| Classification |
Base |
Mappings |
|
|---|---|---|---|
| correct | 5 059 | 5 136 | |
| incorrect | 43 | 43 | |
| not disambiguated | 246 | 169 | |
| Accuracy | 0,93 | 0,96 |
Table 4: Accuracy results for the linking approach.
Relationship Type Classifier
We chose to break down the task of classifying the relationship into two tasks: classifying the type of relationship and the direction of the relationship, as opposed to developing a single classifier that would have to distinguish between 5 possible classes, and with classes that are very unbalanced in terms of representativeness.
This section describes the classifier developed to detect the type of relationship present in a title, with 3 possible classes: opposes, supports and other. All the experiments were carried out with cross-evaluation of 4 partitions.
We evaluated different approaches for the supervised classification of the relationships present in the titles, namely:
- an SVM classifier (Cortes & Vapnik, 1995) 24 with a linear kernel
- a recurrent neural network, a LSTM (Hochreiter & Schmidhuber, 1997) 25
- and Transformer neural network DistilBERT (Sanh et al., 2019) 26.
For the SVM classifier we used as features an approach based on TF-IDF vectors (Salton & Buckley, 1988) 27, pre-processing the title using a pattern in order to identify the relevant context, i.e. the context in the title that contains information describing the relationship:
<Ent1 X Ent2 context>
where X = {“says to”, “responds to”, “suggests to”, “says that, “claims that”, “hopes that”, “argues that”, “considers that”, “suggests that”, “wonders if”, “considers”, “commands”}.
Whenever the pattern doesn’t hold, we use all the words in the title to build the vector, except for the names of the personalities.
The LSTM recurrent neural network was used in a bidirectional architecture, i.e. two LSTM networks are used, both with a dimension of 128, one reading the title from the first to the last word and the other from the last to the first word, and the two final states of each LSTM are concatenated and passed to a linear layer. We used pre-trained embeddings for Portuguese based on the FastText method (skip-gram) of dimension 50 (Hartmann et al., 2017) 28. The network was trained for 5 epochs with a batch size of 8.
The DistilBERT model was trained on the basis of a pre-trained model for Portuguese (Abdaoui et al., 2020) 29 and then fine-tuned on the annotated dataset, i.e.: the weights of all the pre-trained layers were updated taking into account the task of classifying the relation. The network was trained for 5 epochs with a batch size of 8.
| Relationship |
Precision |
Recall |
F1 |
|---|---|---|---|
| opposes | 0,71 | 0,69 | 0,70 |
| supports | 0,65 | 0,69 | 0,67 |
| other | 0,69 | 0,69 | 0,69 |
| macro avg. | 0,69 | 0,69 | 0,69 |
a): SVM with a linear kernel linear.
| Relationship |
Precision |
Recall |
F1 |
|---|---|---|---|
| opposes | 0,75 | 0,64 | 0,69 |
| supports | 0,65 | 0,62 | 0,63 |
| other | 0,65 | 0,75 | 0,70 |
| macro avg. | 0,69 | 0,68 | 0,68 |
b): bi-directional LSTM with Portuguese embeddings.
| Relationship |
Precision |
Recall |
F1 |
|---|---|---|---|
| opposes | 0,74 | 0,76 | 0,75 |
| supports | 0,72 | 0,71 | 0,71 |
| other | 0,72 | 0,71 | 0,72 |
| macro avg. | 0,73 | 0,72 | 0,72 |
c): DistilBERT pre-trained on Portuguese corpora.
Table 5: Precision, Recall and F1 for an evaluation with 4-partitions and cross-validation with different classifiers.
Table 5 describes the results for the various classifiers. There are no marked differences in performance between the 3 classifiers, although the approach using DistilBERT achieved the best results. When analysing the results, we noticed that there are relations that are difficult to classify correctly, particularly those containing idiomatic expressions, for example:
-
José Lello says that Nogueira Leite wants to “abifar uns tachos”
-
Louçã says that Passo Coelho’s “António Borges is the talking cricket”.
Other relationships are ambiguous and difficult to categorise without any other context than the one in the title. In the dataset we have made public, all the headlines contain a URL to the text of the news item.
The results obtained with the approaches described, for Portuguese data, are in line with the results previously reported on English data [(Liang et al. 2019) 16; Park et al. (2021) 17.
Relationship Direction Classifier
The direction classifier has 2 possible classes. As shown in Table 1, the dataset has a bias towards the Ent1 → Ent2 class representing 91.5% of the data. We therefore chose to develop a rule-based approach to detect only the Ent1 ← Ent2 class, and whenever none of the rules are verified, the classifier assigns the Ent1 ← Ent2 class.
We defined rules based on patterns built with morphological and syntactic information (Nivre et al., 2020) 30 extracted from the title with spaCy, using the same model as described in Section 5. We extracted morpho-syntactic information from all the words, including information on conjugation for verbs: person and number. The patterns defined were as follows:
-
PASSIVE_VOICE: we look for patterns
<VERB><ADP>, a verb followed by a proposition. We check whether the passive voice is present and involves the personalities mentioned in the title: whether the Ent1 entity has a dependency on the verb of type acl, whether the verb has a dependency on the Ent1 of type nsubj:pass or whether the verb has a dependency on the Ent2 of type obl:agent. -
VERB_ENT2: detects the morphological pattern
<PUNCT><VERB>Ent2<EOS>, a punctuation mark followed by a verb, and ending with Ent2, restricting the verb to be conjugated in the 3rd person singular of the present tense, and where<EOS>represents the end of the title, meaning that Ent2 is the last word in the title text. -
NOUN_ENT2: checks whether the pattern
<ADJ>?<NOUN><ADJ>?<ADP>Ent2<EOS>is present in the title, i.e.: a noun can be preceded or succeeded by one or more adjectives ending with Ent2, and the noun is restricted to a predefined list of nouns.
Table 6 shows some examples of news headlines and the rules that were applied to detect the Ent1 ← Ent2 class direction. The rules are applied sequentially, in the same order as described here. If none of the patterns are detected in the headline, the classifier assigns the Ent1 → Ent2 class.
| Headline |
Matched Rule |
|---|---|
| Marques Júnior elogiado por Cavaco Silva pela “integridade de carácter” | PASSIVE_VOICE |
| Passos Coelho é acusado de imaturidade política por Santos Silva | PASSIVE_VOICE |
| António Costa vive no “país das maravilhas” acusa Assunção Cristas | VERB_ENT2 |
| Passos Coelho “insultou 500 mil portugueses”, acusa José Sócrates | VERB_ENT2 |
| Maria Luís Albuquerque sob críticas de Luís Amado | NOUN_ENT2 |
| André Ventura diz-se surpreendido com perda de apoio de Cristas | NOUN_ENT2 |
Table 6: Examples of titles in Portuguese and respective rules used to detect the direction of the relationship.
Above in Table 7 we can see the results of this classifier for the annotated data set. The results show that the proposed method correctly classifies a large part of the direction of the Ent1 ← Ent2 class relations, the only class for which rules have been developed, without prejudice to the Ent1 → Ent2 class class.
| Direction |
Precision |
Recall |
F1 |
#Headlines | |
|---|---|---|---|---|---|
| Ent1 → Ent2 | 0,99 | 1,00 | 0,99 | 1,488 | |
| Ent1 ← Ent2 | 0,95 | 0,84 | 0,89 | 129 | |
| weighted avg. | 0,98 | 0,98 | 0,98 | 1,517 |
Table 7: Precision, Recall and F1 for the relationship direction classifier.
Semantic Graph
The components described in the previous section form the process of extracting RDF triples from the collected news headlines.
The extraction process begins by recognising the personalities in the headline and linking them to each personality’s identifier in Wikidata. The extraction process continues if both recognised personalities have been linked with an identifier in Wikidata, otherwise the headline is discarded. The type of relationship present in the title is detected with the DistilBERT model. If the relationship between the personalities in the headline is not classified as other the classifier for the direction of the relationship is also applied to the headline, otherwise the headline is discarded.
For all the headlines considered, the final result is an RDF triple linking the personalities through a relationship of opposition or support supported by a news item. The RDF triples generated are indexed in a SPARQL engine (Jena, 2015) 31 together with a Wikidata sub-graph described in Section 3.
The graph generated has a total of 680 political personalities, 107 political parties and 10,361 news items covering a period of 25 years. It is available online in Terse RDF Triple Language format and can also be explored via a web interface.
Conclusions and Future Work
This work describes in detail the process of constructing a semantic graph from political news headlines.
Using SPARQL queries and referring to the various properties taken from Wikidata for each personality, it is possible to explore support and opposition relationships through aggregations by political parties, public offices, constitutional governments, constituent assemblies, among others, thus being able to formulate more complex queries, for example:
- “Ministers of the XXII Constitutional Government who were opposed by PCP or BE personalities."
The answer is the list of ministers and the articles that support the opposition relations coming from the BE.
One of the limitations of this work is that the headline doesn’t contain enough information to realise what kind of relationship or feeling exists from one personality to another, or the presence of idiomatic expressions, which make automatic classification difficult.
As future work we would like to explore the text of the news item in order to complement the headline and improve the detection of the relationship. Also based on the text of the headline, the relationships could be enriched by categorising them into topics, giving the relationship another dimension, a context for the feeling of support or opposition.
Some headlines contain a mutual relationship, for example:
- “Sócrates and Alegre exchange accusations over co-incineration"
- “Pinto da Costa hits back at Pacheco Pereira’s criticisms"
could be categorised as Ent1↔Ent2, indicating in this case that both personalities are accusing each other.
This work also leaves open the possibility of carrying out various studies based on the structure of the graph, for example: finding communities of support and opposition as a function of time and verifying the changes within these communities. Political triangles can also be studied: if two political personalities, X and Y, always accuse or defend a third personality Z, what is the typical relationship expected between X and Y?
Acknowledgements
We would like to thank Nuno Feliciano for all his comments during the preparation of this work and the Arquivo.PT team for providing access to the archived data via an API and for considering this work for the Arquivo.PT 2021 awards. To Edgar Felizardo and Tiago Cogumbreiro for their extensive revisions to the article, and also to reviewers Sérgio Nunes and José Paulo Leal for all their comments and corrections.
References
-
Getting the Most out of Wikidata: Semantic Technology Usage in Wikipedia’s Knowledge Graph
- Authors: Stanislav Malyshev, Markus Krötzsch, Larry González, Julius Gonsior, Adrian Bielefeldt
- Conference: Proceedings of the 17th International Semantic Web Conference (ISWC’18)
- Year: 2018
- DOI: N/A
-
RDF 1.1 Primer W3C Working Group Note
- Authors: Guus Schreiber, Yves Raimond
- Year: 2014
- URL: RDF 1.1 Primer W3C Working Group Note
-
SPARQL 1.1 Query Language
- Authors: Eric Prud’hommeaux, Steve Harris, Andy Seaborne
- Year: 2013
- URL: SPARQL 1.1 Query Language
-
David Zimbra, Ahmed Abbasi, Daniel Zeng, and Hsinchun Chen
- Title: The State-of-the-Art in Twitter Sentiment Analysis: A Review and Benchmark Evaluation
- Year: 2018
- Issue Date: June 2018
- Journal: ACM Trans. Manage. Inf. Syst.
- Volume: 9
- Number: 2
- ISSN: 2158-656X
- DOI: 10.1145/3185045
- Month: August
- Article No: 5
- Number of Pages: 29
-
Maria Pontiki, Dimitris Galanis, Haris Papageorgiou, Ion Androutsopoulos, Suresh Manandhar, Mohammad AL-Smadi, Mahmoud Al-Ayyoub, Yanyan Zhao, Bing Qin, Orphée De Clercq, Véronique Hoste, Marianna Apidianaki, Xavier Tannier, Natalia Loukachevitch, Evgeniy Kotelnikov, Nuria Bel, Salud María Jiménez-Zafra, and Gülşen Eryiğit
- Title: SemEval-2016 Task 5: Aspect Based Sentiment Analysis
- Book Title: Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016)
- Year: 2016
- Month: June
- Pages: 19–30
- DOI: 10.18653/v1/S16-1002
-
Balahur, Alexandra, Ralf Steinberger, Erik van der Goot, Bruno Pouliquen, and Mijail Kabadjov
- Title: Opinion Mining on Newspaper Quotations
- Book Title: Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology-Volume 03
- Year: 2009
- Pages: 523–526
- DOI: Link
-
Balahur, Alexandra, Ralf Steinberger, Mijail Kabadjov, Vanni Zavarella, Erik van der Goot, Matina Halkia, Bruno Pouliquen, and Jenya Belyaeva
- Title: Sentiment Analysis in the News
- Book Title: Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10)
- Year: 2010
- Month: May
- Pages: 655–662
- DOI: Link
-
Automatic Creation of a Reference Corpus for Political Opinion Mining in User-Generated Content
- Authors: Luís Sarmento, Paula Carvalho, Mario J. Silva, Eugénio de Oliveira
- Conference: Proceedings of the 1st International CIKM Workshop on Topic-Sentiment Analysis for Mass Opinion
- Year: 2009
- DOI: 10.1145/1651461.1651468
- Pages: 29–36
-
Tracking politics with POWER
- Authors: Silvio Moreira, David S. Batista, Paula Carvalho, Francisco M. Couto, Mario J. Silva
- Journal: Program: electronic library and information systems
- Volume: 47
- Number: 2
- Year: 2013
- DOI: Link
-
An Annotated Corpus for Sentiment Analysis in Political News
- Authors: Gabriel Domingos de Arruda, Norton Trevisan Roman, Ana Maria Monteiro
- Conference: Proceedings of the 10th Brazilian Symposium in Information and Human Language Technology
- Year: 2015
- DOI: 10.1145/2835988.2835995
- Pages: 101-110
-
A dataset for Sentiment analysis of Entities in News headlines (SEN)
- Authors: Katarzyna Baraniak, Marcin Sydow
- Journal: Procedia Computer Science
- Volume: 192
- Year: 2021
- DOI: 10.1016/j.procs.2021.09.136
- Pages: 3627-3636
-
What Do You Mean by Relation Extraction? A Studyurvey on Datasets and Study on Scientific Relation Classification
- Authors: Elisa Bassignana, Barbara Plank
- Conference: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop
- Year: 2022
- DOI: 10.18653/v1/2022.acl-srw.7
- Pages: 67-83
-
Learning to Extract International Relations from Political Context
- Authors: Brendan O’Connor, Brandon M. Stewart, Noah A. Smith
- Conference: Proceedings of the 51st Annual Meeting of the ACL (Volume 1: Long Papers)
- Year: 2013
- URL: PDF
-
No Permanent Friends or Enemies: Tracking Relationships between Nations from News
- Authors: Xiaochuang Han, Eunsol Choi, Chenhao Tan
- Conference: Proceedings of the 2019 Conference of the North American Chapter of the ACL: Human Language Technologies, Volume 1 (Long and Short Papers)
- Year: 2019
- DOI: 10.18653/v1/N19-1167
-
Feuding Families and Former Friends: Unsupervised Learning for Dynamic Fictional Relationships
- Authors: Mohit Iyyer, Anupam Guha, Snigdha Chaturvedi, Jordan Boyd-Graber, Hal Daumé III
- Conference: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
- Year: 2016
- DOI: 10.18653/v1/N16-1180
- Pages: 1534-1544
-
Liang, Shuailong, Olivia Nicol, and Yue Zhang
- Title: Who blames whom in a crisis? detecting blame ties from news articles using neural networks
- Book Title: Proceedings of the AAAI Conference on Artificial Intelligence
- Volume: 33
- Number: 01
- Year: 2019
- Pages: 655–662
- DOI: Link
-
Park, Kunwoo, Zhufeng Pan, and Jungseock Joo
- Title: Who Blames or Endorses Whom? Entity-to-Entity Directed Sentiment Extraction in News Text
- Book Title: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021
- Year: 2021
- Month: August
- DOI: 10.18653/v1/2021.findings-acl.358
- Pages: 4091–4102
-
ElasticSearch: The Definitive Guide
- Authors: Clinton Gormley, Zachary Tong
- Year: 2015
- ISBN: 1449358543
- Publisher: O’Reilly Media, Inc.
- Edition: 1st
-
Search the Past with the Portuguese Web Archive
- Authors: Daniel Gomes, David Cruz, João Miranda, Miguel Costa, Simão Fontes
- Conference: 22nd International World Wide Web Conference
- Year: 2013
- DOI: 10.1145/2487788.2487934
-
Evaluating CETEMPúblico, a Free Resource for Portuguese
- Authors: Diana Santos, Paulo Rocha
- Conference: Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics
- Year: 2001
- URL: PDF
-
CHAVE: Topics and Questions on the Portuguese Participation in CLEF
- Authors: Diana Santos, Paulo Rocha
- Conference: Working Notes for CLEF 2004 Workshop co-located with the 8th European Conference on Digital Libraries (ECDL 2004)
- Year: 2004
- URL: PDF
-
spaCy: Industrial-strength Natural Language Processing in Python
- Authors: Matthew Honnibal, Ines Montani, Sofie Van Landeghem, Adriane Boyd
- Year: 2020
- Publisher: Zenodo
- DOI: 10.5281/zenodo.1212303
-
Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida
- Author: Matthew A. Jaro
- Journal: Journal of the American Statistical Association
- Volume: 84
- Number: 406
- Year: 1989
- DOI: 10.1080/01621459.1989.10478785
-
Support-Vector Networks
- Authors: Corinna Cortes, Vladimir Vapnik
- Journal: Machine Learning
- Volume: 20
- Number: 3
- Year: 1995
- Pages: 273-297
- DOI: 10.1007/BF00994018
-
Long Short-Term Memory
- Authors: Sepp Hochreiter, Jürgen Schmidhuber
- Journal: Neural Comput.
- Volume: 9
- Number: 8
- Year: 1997
- DOI: 10.1162/neco.1997.9.8.1735
- Pages: 1735–1780
-
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- Authors: Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf
- Conference: 2019 Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing - NeurIPS Edition (EMC2-NIPS)
- Year: 2019
- DOI: N/A
- Pages: N/A
-
Term-Weighting Approaches in Automatic Text Retrieval
- Authors: Gerard Salton, Chris Buckley
- Journal: Information Processing & Management
- Volume: 24
- Number: 5
- Year: 1988
- DOI: 10.1016/0306-4573(88)90021-0
-
Portuguese Word Embeddings: Evaluating on Word Analogies and Natural Language Tasks
- Authors: Nathan Hartmann, Erick Fonseca, Christopher Shulby, Marcos Treviso, Jéssica Silva, Sandra Aluísio
- Conference: Proceedings of the 11th Brazilian Symposium in Information and Human Language Technology
- Year: 2017
- DOI: 10.18653/v1/W17-6615
- Pages: 122-131
-
Load What You Need: Smaller Versions of Multilingual BERT
- Authors: Amine Abdaoui, Camille Pradel, Grégoire Sigel
- Conference: Proceedings of SustaiNLP: Workshop on Simple and Efficient Natural Language Processing
- Year: 2020
- DOI: 10.18653/v1/2020.sustainlp-1.16
- Pages: 119-123
-
Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection
- Authors: Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Jan Hajič, Christopher D. Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, Daniel Zeman
- Conference: Proceedings of the 12th Language Resources and Evaluation Conference
- Year: 2020
- DOI: 10.18653/v1/2020.lrec-1.497
- Pages: 4034-4043
- ISBN: 979-10-95546-34-4
-
A Free and Open Source Java Framework for Building Semantic Web and Linked Data Applications
- Author: Apache Jena
- Year: 2015
- URL: Official Website
relationship-extraction dataset semantic-web political-science 