Text Summarisation Techniques
Text summarisation resumes the information contained in a text, into a shorter version, still capturing the original semantics. This can be achieved by selecting representative words or phrases from the original text and combining them to make a summary (extractive), or by writing a summary as a human would do, by generating a textual summary of the main content in the original text (abstractive). This post quickly reviews some of the recent works on NLP Text summarisation using both approaches.
Extractive
Extractive approaches select representative phrases from the original text and combine them to make a summary, in its essence, they score or measure some sort of saliency or ranking of the sentences contained in a text. It’s language and domain-agnostic, doesn’t require any training data and the generated summaries are grammatically and factually correct.
However, the generated summary may not cover all important content or be longer than necessary, containing unnecessary parts that may not be needed in the summary, moreover, it might have a reduction of semantic quality or cohesion and possible wrong connections between selected sentences. Here are some (old) popular approaches, and some more recent ones:
2004 - TextRank
- TextRank: Bringing Order into Text
- Inspired by PageRank
- This page contains a very good resume of the algorithm: Textrank for Summarizing Text
- It was part of gensim package - removed on 4.0.0 - still present in older releases
2011 - LexRank
- LexRank: Graph-based Lexical Centrality as Salience in Text Summarization
- A connectivity matrix based on intra-sentence cosine similarity is used as the adjacency matrix of the graph representation of sentences.
- Uses eigenvector centrality to select sentences.
2019 - HIBERT
- Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization
- Relies on two encoders to obtain the representation of a document
- A sentence encoder to transform each sentence into a vector
- A document encoder learns sentence representations based on their surrounding context sentences
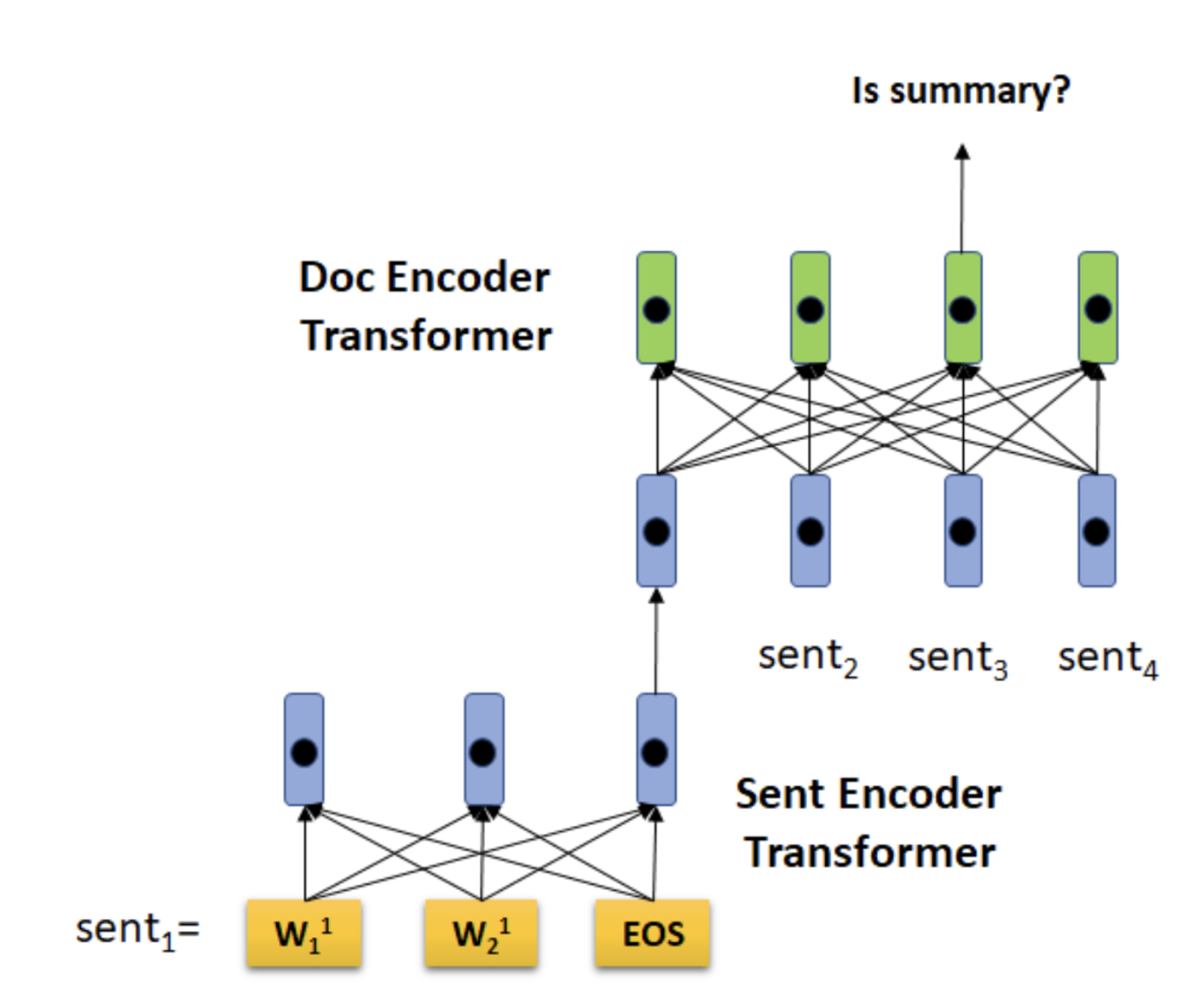
2019 - BERTSumExt
- Text Summarization with Pretrained Encoders
- An encoder creates sentence representations and a classifier predicts which sentences should be selected as summaries
- Has a document-level encoder based on BERT to obtain sentence representations
- The modification mainly consists of surrounding each sentence of the text with:
- a [CLS] (which represents the entire sentence)
- and [SEP] (which represents the boundary between two sentences)
- assigning different segment embeddings for every pair of sentences
- Sentence-level contextual representations fed to a classifier for binary classification
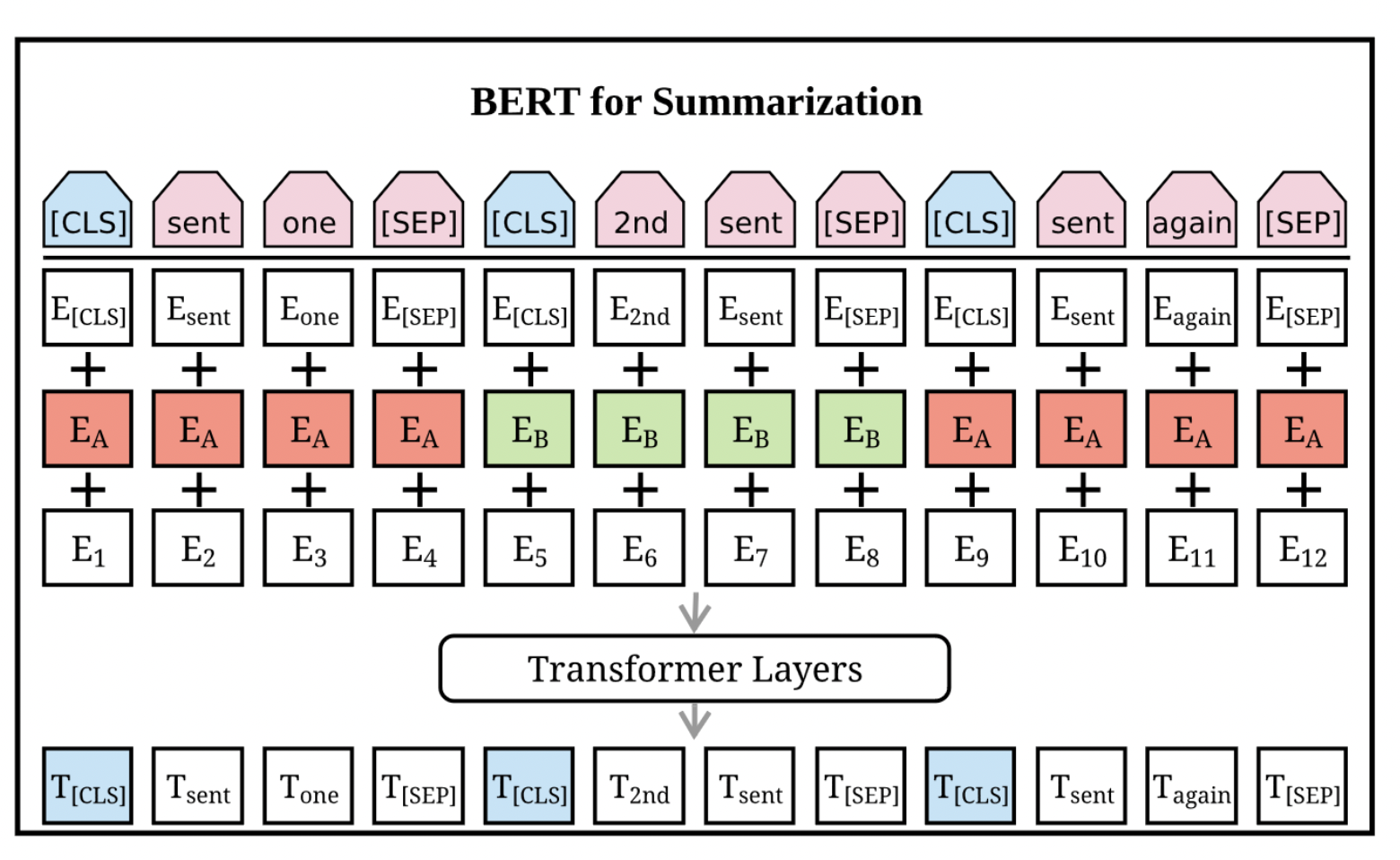
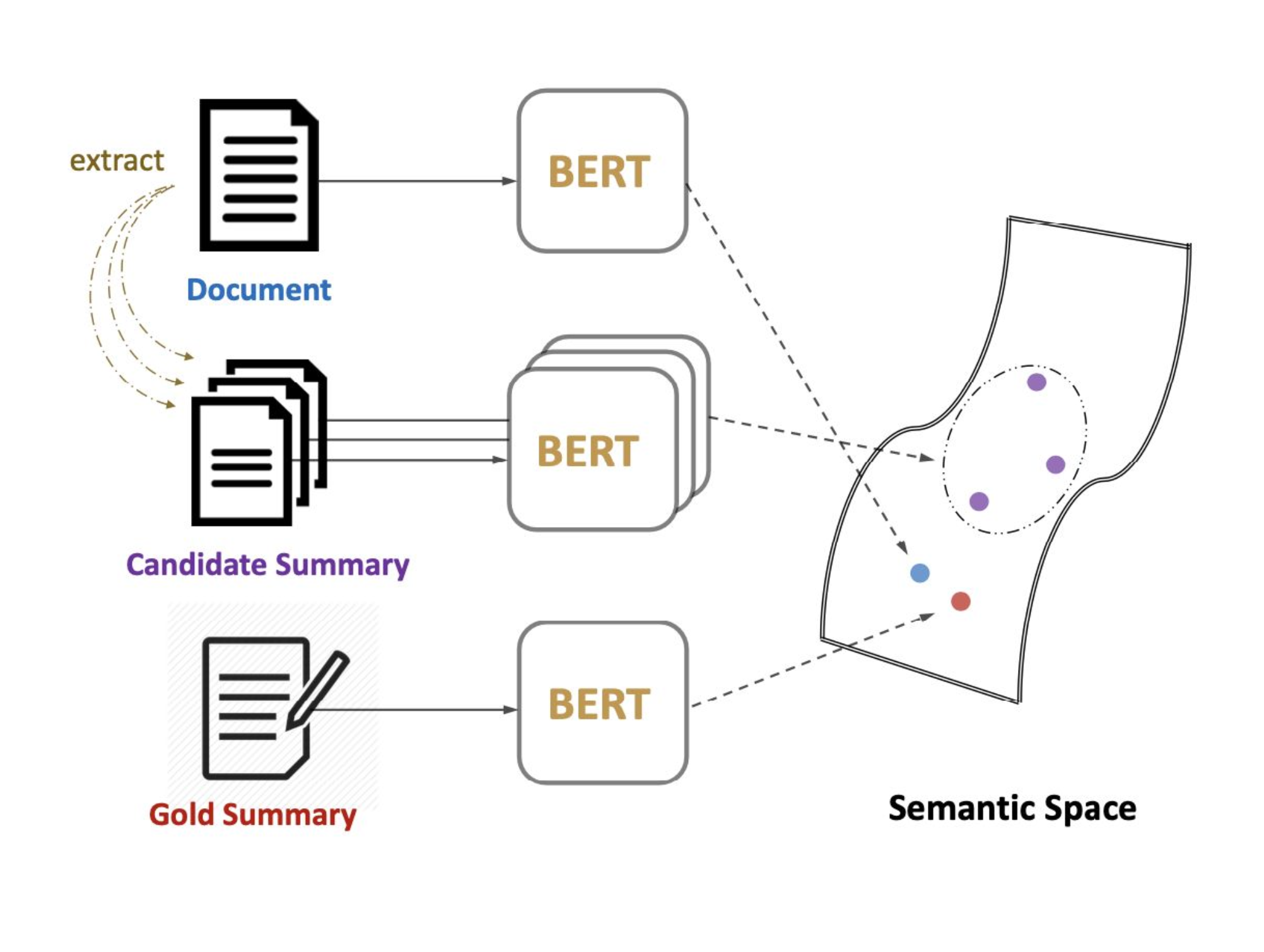
2020 - MatchSum
- Extractive Summarization as Text Matching
- The source document and candidate summaries will be extracted from the original text and matched in a semantic space
- Siamese-BERT architecture to compute the similarity between the source document and the candidate summary
- Leverages the pre-trained BERT in a Siamese network structure to derive semantically meaningful text embeddings that can be compared using cosine-similarity
Abstractive
Generated a concise summary capturing the essence of the original text. This approach can decrease the amount of summary text, by removing redundancy and obtaining an expressive summary. But, it seeds a precise syntactic and semantic representation of text data and may contain factual errors due to the algorithm not grasping the text’s context well enough.
Earlier approaches would be templated-based or rule-based, the Seq2Seq (encoder-decoder) based on vanilla RNN/LSTM or augmented with Attention Mechanism was another popular approach exploring the generative capability of recurrent neural networks, and more recently the Encoder-Decoder mechanism based on the Transformer dominate most of the new approaches:
2019 - BERTSumAbs
- Text Summarization with Pretrained Encoders
- Adopts an encoder-decoder architecture, combining the same pre-trained BERT encoder and a randomly-initialised Transformer decoder
- Training separates the optimisers of the encoder and the decoder in order to accommodate the fact that the encoder is pre-trained while the decoder must be trained from scratch
- Propose a two-stage fine-tuning approach, where we first fine-tune the encoder on the extractive summarisation task and then fine-tune it on the abstractive summarisation task
- Combine extractive and abstractive objectives, a two-stage approach: the encoder is fine-tuned twice, first with an extractive objective and subsequently on the abstractive summarisation task.
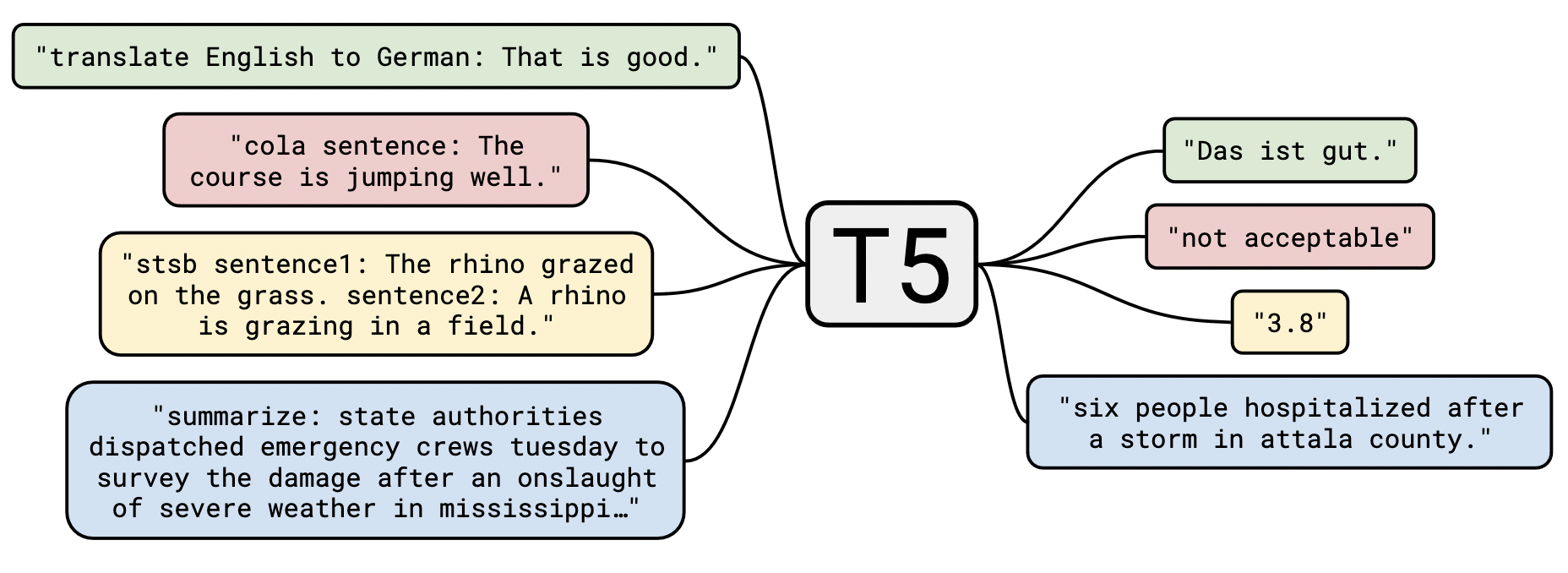
2019 T5 - Text-to-Text Transfer Transformer
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Pre-trained Transformer encoder-decoder unifying many tasks as the same text-to-text problem
- Input of the encoder is a task description (e.g., “Summarize: ”) followed by task input (e.g., a sequence of tokens from an article), and the decoder predicts the task output (e.g., a sequence of tokens summarizing the input article)
- T5 is trained to generate some target text conditional on input text to perform as text-to-text
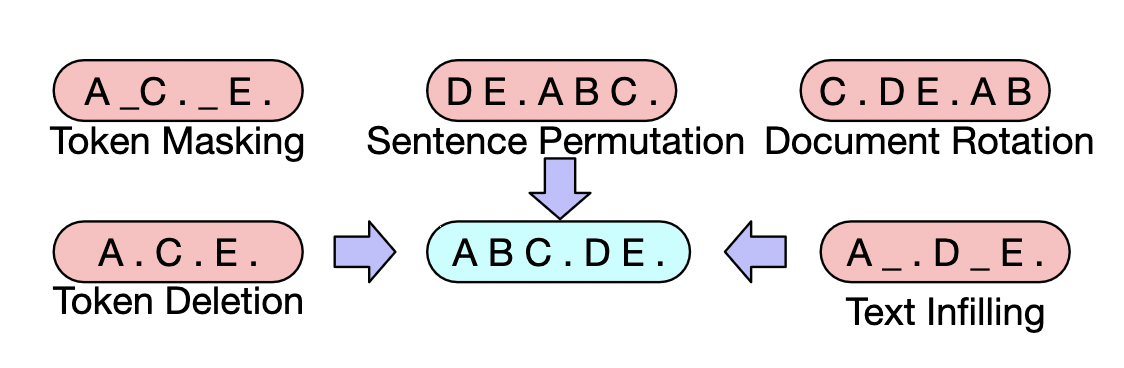
2020 BART
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Trained on reconstructing documents to which noise has been introduced
- The noise may take multiple forms, ranging from removing tokens to permuting sentences
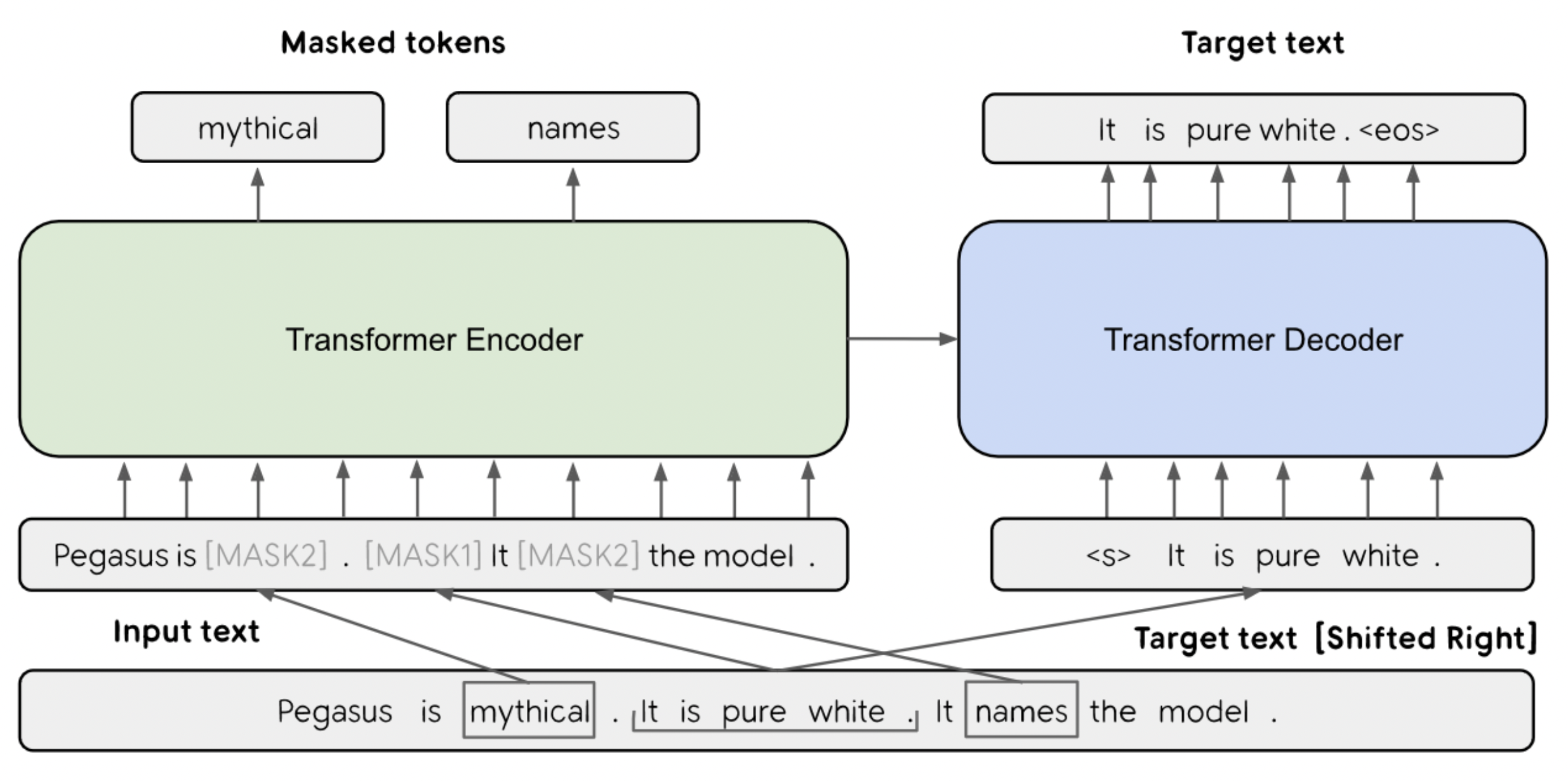
2020 PEGASUS
- PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
- Specifically designed and pre-trained neural network for the automatic text summarisation task
- Pre-training self-supervised objective - gap-sentence generation - for Transformer encoder-decoder models
- Fine-tuned on 12 diverse summarisation datasets
- Select and mask whole sentences from documents, and concatenate the gap sentences into a pseudo-summary.
Comparative Summarisation
| Name | Method | Max. Input | Code | Pre-Trained models | Languages |
|---|---|---|---|---|---|
| TextRank (2004) | Extractive | - | gensim | - | - |
| LexRank (2011 | Extractive | - | lexrank | - | - |
| BertSum (2019) | Both | ? | PreSumm | see code | English |
| HIBERT (2019) | Extractive | ? | HIBERT | see code | English |
| T5 (2019) | Abstractive | 1024 - 16384 | T5x | huggingface.co | several |
| MatchSum (2020) | Extractive | ? | MatchSum | see code | English |
| BART (2020) | Abstractive | 1024 | fairseq | huggingface.co | several |
| PEGASUS (2020 | Abstractive | ? | pegasus | huggingface.co | several |
Evaluation
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) - Recall
- compare produced summary against reference summary by overlapping n-grams
- ROUGE-N: report with different n-grams size
- ROUGE-L: instead of n-gram overlap measures the Longest Common Subsequence
- BLEU (Bilingual Evaluation Understudy) - Precision
- compare the reference summary against the produced summary
- how much the words (and/or n-grams) in the reference appeared in the machine summary
- Limitations
- always need a reference summary
- just measuring string overlaps
- alternative is to have a human evaluation
text-summarisation transformers 