Sentence Transformers
The sentence-transformers proposed in Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks is an effective and efficient way to train a neural network such that it represents good embeddings for a sentence or paragraph based on the Transformer architecture. In this post I review mechanism to train such embeddings presented in the paper.
Introduction
Measuring the similarity of a pair of short-text (.e.g: sentences or paragraphs) is a common NLP task. One can achieve this with BERT, using a cross-encoder, concatenating both sentences with a separating token [SEP], passing this input to the transformer network and the target value is predicted, in this case, similar or not similar.
But, this approach grows quadratically due to too many possible combinations. For instance, finding in a collection of \(n\) sentences the pair with the highest similarity requires with BERT \(n \cdot(n−1)/2\) inference computations.
Alternatively one could also rely on BERT’s output layer, the embeddings, or use the output of the first token, i.e.: the [CLS] token, but as the authors shows this often leads to worst results than just using static-embeddings, like GloVe embeddings (Pennington et al., 2014).
To overcame this issue, and still use the contextual word embeddings representations provided by BERT (or any other Transformer-based model) the authors use a pre-trained BERT/RoBERTa network and fine-tune it to yield useful sentence embeddings, meaning that semantically similar sentences are close in vector space.
Fine-Tuning BERT for Semantically (Dis)Similarity
The main architectural components of this approach is a Siamese Neural Network, a neural network containing two or more identical sub-networks, whose weights are updated equally across both sub-networks.
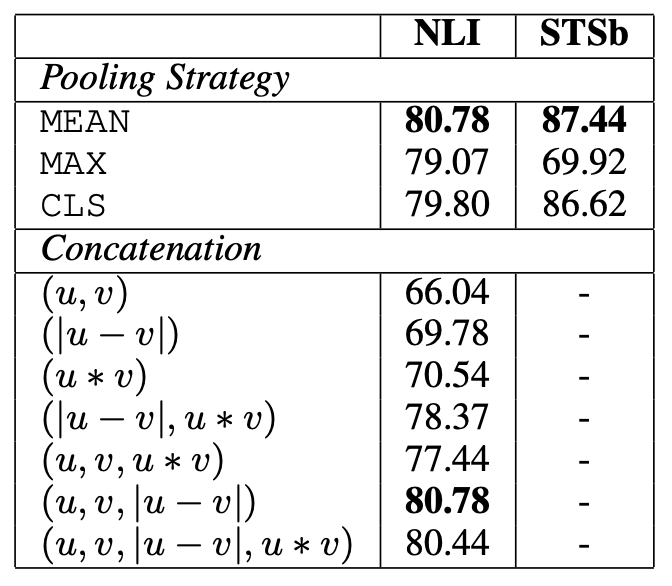
The training procedure of the network is the following. Each input sentence is feed into BERT, producing embeddings for each token of the sentence. To have fixed-sized output representation the authors apply a pooling layer, exploring three strategies:
-
[CLS]-token
-
MEAN-strategy: computing the mean of all output vectors
-
MAX-strategy: computing a max-over-time of the output vectors
They experiment with 3 different network objective function depending on the training data:
Classification:
\[o = \text{softmax}(Wt(u, v, |u − v|))\]concatenating the sentence embeddings \(u\) and \(v\) with the element-wise difference \(\vert u − v \vert\) and multiply it with the trainable weight \(W_t \in R^{3n×k}\).
Regression:
\[cos(u,v)\]simply the cosine between the two sentence embeddings.
Triplet Objective Function:
\[max(||s_{a} − s_{p}|| − || s_{a} − s_{n} || + ε, 0)\]a baseline anchor \(a\) input is compared to a positive \(p\) input and a negative \(n\) input. The distance from the baseline \(a\) to the positive \(p\) input is minimized, and the distance from the baseline \(a\) to the negative \(n\) is maximized. As far as I’ve understood this objective function is only used in one experiment with the Wikipedia Sections Distinction dataset.
Training Data
The objective function (classification vs. regression) depends on the training data. For the classification objective function, the authors used the The Stanford Natural Language Inference (SNLI) Corpus, a collection of 570,000 sentence pairs annotated with the labels:
- contradiction
- entailment
- neutral
The The Multi-Genre NLI Corpus containing 430,000 sentence pairs and covers a range of genres of spoken and written text.
For the regression objective function, the authors trained on the training set of the Semantic Textual Similarity (STS) benchmark dataset from SemEval.
Training: fine-tuning
In order to fine-tune BERT and RoBERTa, the authors used a Siamese Neural Network (SNN) strategy to update the weights such that the produced sentence embeddings are semantically meaningful.
An SNNs can be used to find the similarity of the inputs by comparing its feature vectors, so these networks learn a similarity function that takes two inputs and outputs 1 if they belong to the same class and zero other wise,
It learn parameters such that, if the two sentences are similar:
\[|| f(x_1) - (f(x_2)||^2 \text{ is small}\]and if the two sentences are dissimilar:
\[|| f(x_1) - (f(x_2) ||^2 \text{ is large}\]where \(f(x)\) is embedding of \(x\).
Configuration parameters
- batch-size: 16,
- Adam optimizer with learning rate 2e−5,
- linear learning rate warm-up over 10% of the training data.
- MEAN as the default pooling strategy is .
- 3-way softmax-classifier objective function for one epoch.
Evaluation
The authors evaluated their approach on several datasets common Semantic Textual Similarity (STS) tasks, using the cosine-similarity to compare the similarity between two sentence embeddings, in opposition to learning a regression function that maps two sentence embeddings to a similarity score. They also experimented with Manhatten and negative Euclidean distances as similarity measures, but the results remained roughly the same.
To recapitulate BERT and RoBERTa are fine-tuned using the training described above, and the resulting model are used to generate embeddings for sentences, whose similarity is measured by the cosine.
- SemEval 2012-2016 - Semantic Textual Similarity (STS) datasets: 2012, 2013, 2014, 2015, 2016
- SICK (Sentences Involving Compositional Knowledge)
- SemEval-2017 Task 1: STSimilarity Multilingual and Crosslingual Focused Evaluation
The authors also carry other experiments with a few other datasets, but I will refer the reader to the the original paper for further details.
Ablation Study
The study explored different methods to concatenate the sentence embeddings for training the softmax classifier in the process of fine-tuning a BERT/RoBERTa transformer model.
According to the authors the most important component is the element-wise difference \(\vert u − v \vert\) which measures the distance between the dimensions of the two sentence embeddings, ensuring that similar pairs are closer and dissimilar pairs are further apart.
Implementation and others
The sentence-transformers package gain popularity in the NLP community and can be used for multiple tasks as semantic text similarity, semantic search, retrieve and re-rank, clustering and others, see the official webpage SBERT for several tutorials and API documentation
One of the authors of the paper Nils Reimers has made several talks on ideas and approaches levering on sentence-transformers, here are two I’ve found interesting:
References
sentence-transformers triplet-loss embeddings fine-tuning 