Sentence Transformer Fine-Tuning - SetFit
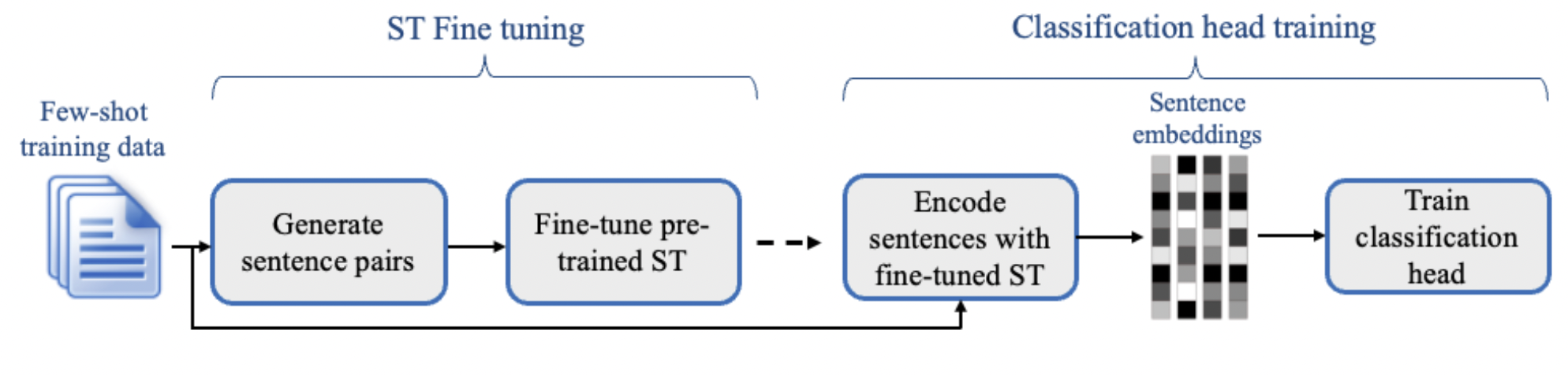
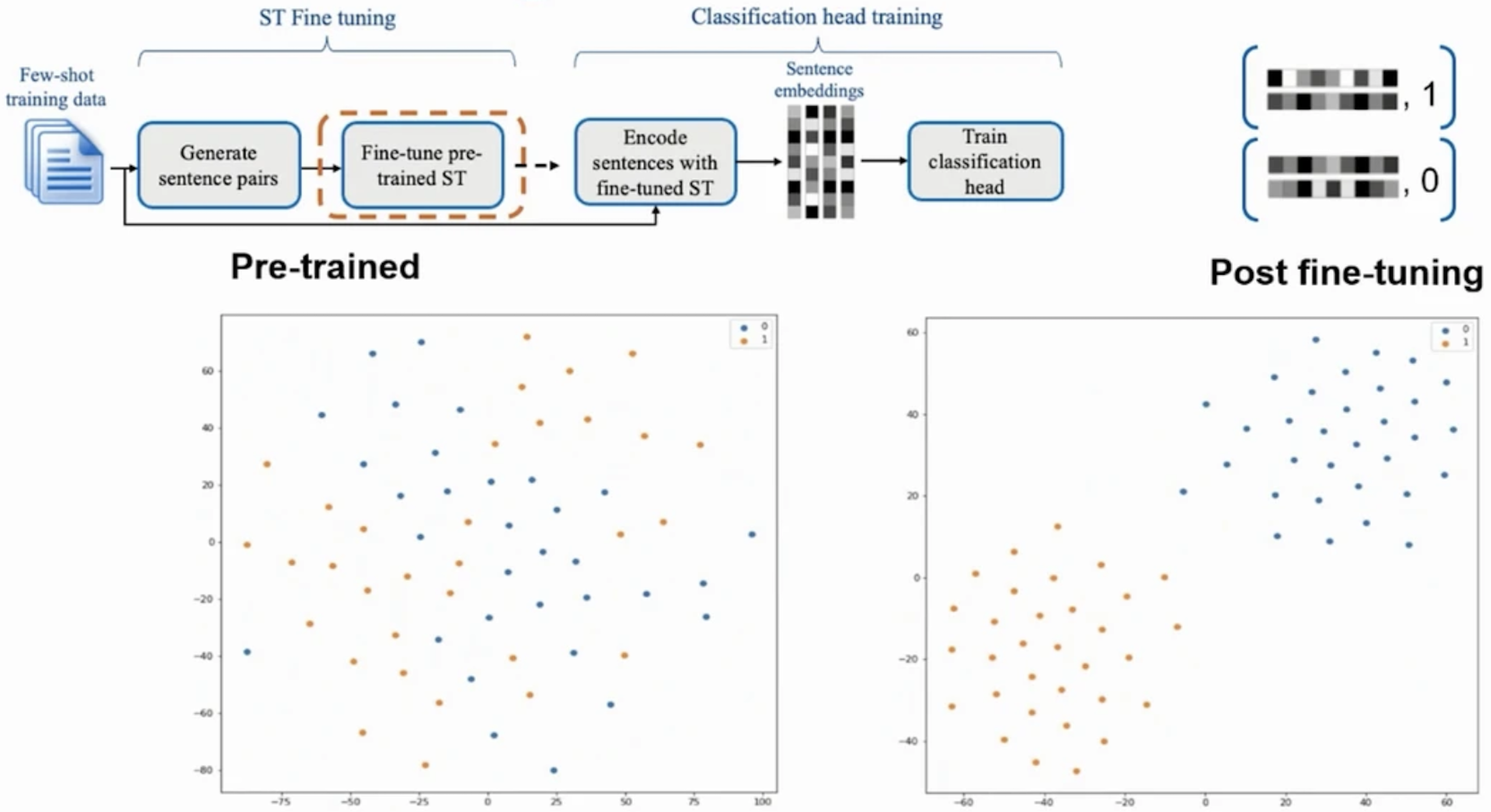
Sentence Transformers Fine-Tunning (SetFit) is a technique to mitigate the problem of a few annotated samples by fine-tuning a pre-trained sentence-transformers model on a small number of text pairs in a contrastive learning manner. The resulting model is then used to generate rich text embeddings, which are then used to train a classification head, resulting in a final classifier fine-tuned to the specific dataset.
Contrastive Learning
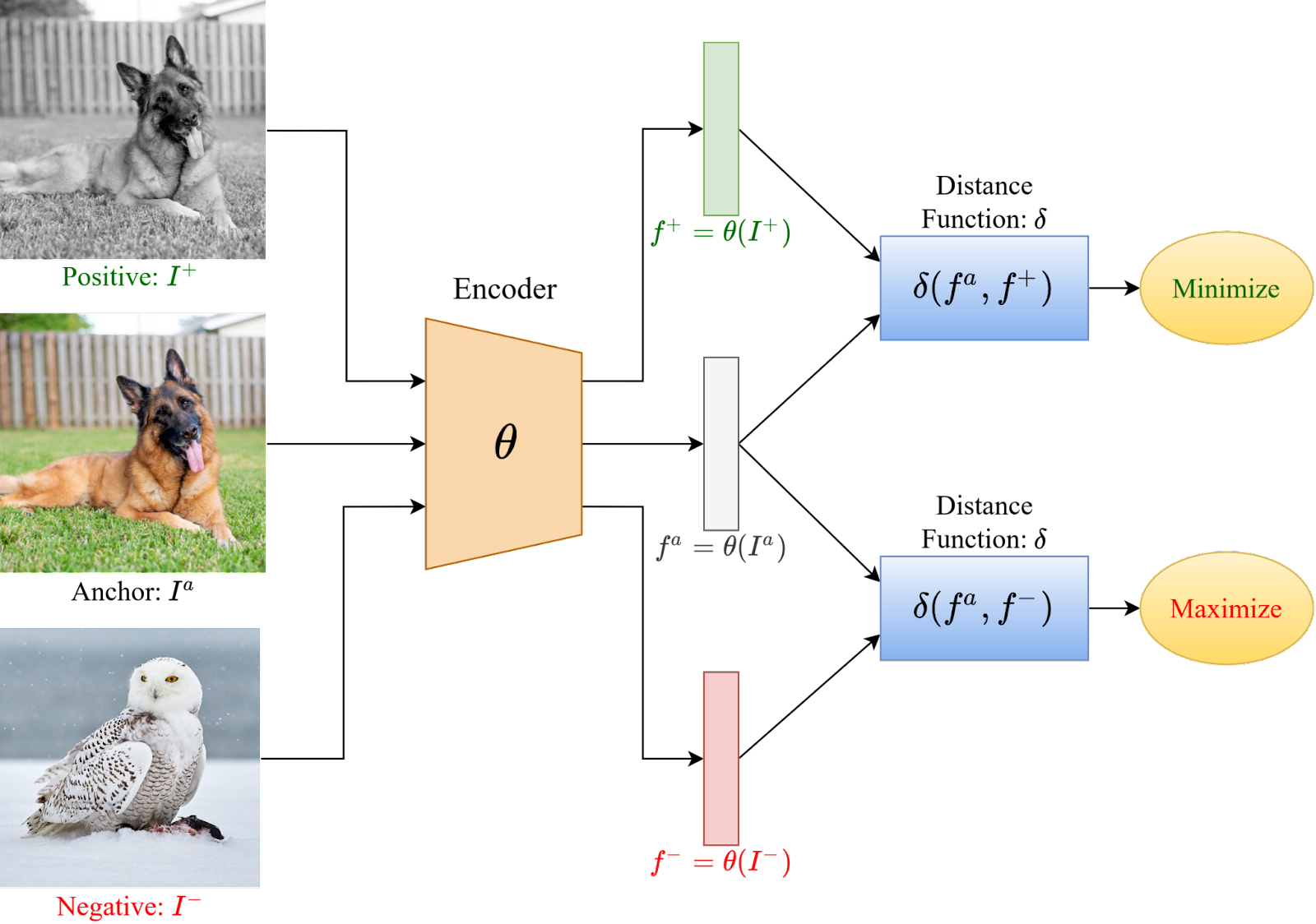
The first step relies on a sentence-transformer model and adapts a contrastive training approach that is often used for image similarity detection (Koch et al., 2015).
The basic contrastive learning framework consists of selecting a data sample, called anchor a data point belonging to the same distribution as the anchor, called the positive sample, and another data point belonging to a different distribution called the negative sample, as shown in Figure 1.
The model tries to minimize the distance between the anchor and positive sample and, at the same time, maximize the distance between the anchor and the negative samples. The distance function can be anything in the embedding space.
Selecting Positive and Negative Triples
Given a dataset of \(K\) labeled examples
\[D = {(x_i, y_i)}\]where \(x_i\) and \(y_i\) are sentences and their class labels, respectively.
For each class label \(c \in C\) in the dataset we need to generate a set of positive triples:
\[T_{p}^{c} = {(x_{i},x_{j}, 1)}\]where \(x_{i}\) and \(x_{j}\) are pairs of randomly chosen sentences from the same class \(c\), i.e \((y_{i} = y_{j} = c)\)
and, also a set of negative triples:
\[T_{n}^{c} = {(x_{i} , x_{j} , 0)}\]where \(x_{i}\) and \(x_{j}\) are randomly chosen sentences from different classes such that \((y_{i} = c, y_{j} \neq c)\).
Building the Contrastive Fine-tuning Dataset
The contrastive fine-tuning data set \(T\) is produced by concatenating the positive and negative triplets across all class labels:
\[T = { (T_{p}^{0},T{n}^{0}), (T_{p}^{1},T{n}^{1}), \ldots, (T_{p}^{|C|}, T_{n}^{|C|}) }\]\(\vert C \vert\) is the number of class labels
\[\vert T \vert = 2R \vert C \vert\]is the number of pairs in \(T\) and \(R\) is a hyperparameter.
Fine-Tuning
The contrastive fine-tuning dataset is then used to fine-tune the pre-trained sentence-transformer model using a
contrastive loss function. The contrastive loss function is designed to minimize the distance between the anchor and
positive samples and maximize the distance between the anchor and negative samples.
Training Classification Head
This step is a standard supervised learning task, where the fine-tuned sentence-transformer model is used to generate embeddings for the training data, and a classification head is trained on top of the embeddings to predict the class labels.
References
-
Original paper: Efficient Few-Shot Learning Without Prompts (PDF)
-
Weng, Lilian. (May 2021). Contrastive representation learning. Lil’Log
-
Sentence Transformer Fine-Tuning post on Towards Data Science by Moshe Wasserblat
-
Learning a Similarity Metric Discriminatively, with Application to Face Verification
sentence-transformers triplet-loss contrastive-learning fine-tuning 