Open Information Extraction in Portuguese
In this post I will present one of the first proposed Open Information Extraction systems, which is very simple and effective, relying only on part-of-speech tags. I also implement it and apply it to Portuguese news articles.
But first a small introduction, Information Extraction, in an NLP context, deals with the problem of extracting structured information from text. For a computer, the text is just a sequence of bytes, with no semantic meaning whatsoever.
A possible approach to extract structured information from text is to extract semantic relationships or semantic triples, for instance, named entities (e.g., persons, locations, organisations), and the semantic relationships between them.
Semantic relationships are typically represented by triples in the form <e1, rel, e2>, where e1 and e2 are noun-phrases/entities of a relationship, and rel is the type of relationship relating the two noun phrases.
For instance, given the following sentence:
"The linguist Noam Chomsky was born in East Oak Lane neighbourhood of Philadelphia."
we first identify the named entities, in this case, three different named entities are recognized.

Then, two different relationships can be extracted between the recognized named entities:
<Noam Chomsky, place-of-birth, East Oak Lane>
<East Oak Lane, part-of, Philadelphia>
Typically (or until 2007) most systems aimed at extracting relationships with known a priori relationship types (i.e., place-of-birth, part-of, etc.), and each target relationship is learned from training data or defined by hand-made rules.
Another approach is Open Information Extraction (OIE) (Etzioni et al. (2008), Banko, et al. (2007)), which is suited when the target relations are unknown and the textual data is heterogeneous.
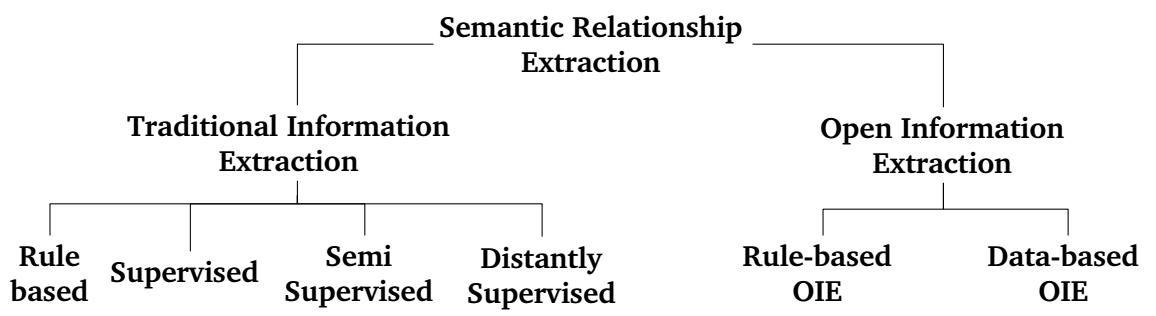
OIE techniques, on the other hand, extract all possible relationship types from a given collection of documents. OIE can be divided into two main categories, data- and rule-based.
Rule-based OIE relies on hand-crafted patterns from PoS-tagged text or rules operating on dependency parse trees. Data-based OIE generates patterns based on training data represented by means of a dependency tree or PoS-tagged text.
The figure below shows a taxonomy of different methods to perform relationship extraction. If you are interested you can also check Chapter 2 of my PhD thesis for a review of work in relationship extraction.
ReVerb: Identifying Relations for Open Information Extraction
ReVerb (Fader et al., 2011) extracts relationships based on a simple constraint, every relational phrase, i.e. the sequence of words connecting two entities, must be either:
- a verb (e.g., invented),
- a verb followed immediately by a preposition (e.g., located in),
- a verb followed by nouns, adjectives, or adverbs ending in a preposition (e.g., has an atomic weight of)
This corresponds to the PoS-tags pattern shown in the figure below

If there are multiple possible matches for a single verb, the longest possible match is chosen. If the pattern matches multiple adjacent sequences, ReVerb merges them into a single relation phrase.
During extraction, the system first looks for a matching relational phrase and then for the arguments (e1, e2) of the relationship, thus avoiding confusing a noun in the relational phrase for an argument.
Extracting semantic relationships from Portuguese
For English, there are several software packages ready to use out-of-the-box to perform simple NLP tasks: such as part-of-speech tagging, dependency parsing, named-entity recognition, etc.
But for Portuguese, and many other languages, that’s not the case, therefore I was curious whether I could quickly and easily adapt ReVerb to Portuguese and extract triples from a collection of documents.
I also did a small change from the original ReVerb algorithm, instead of looking for noun phrases, I first tagged all the named entities (i.e., PER, LOC, ORG) in a document collection, and then tried to find relational phrases, according to the pattern based on PoS, which connect the named-entities in a relationship.
I used three main resources for a running quick experiment:
I) Polyglot, is an NLP library supporting several languages, including Portuguese, performing:
-
sentence boundary detection
-
part-of-speech tagging
-
named-entity recognition (NER)
I had some troubles installing PyICU which is needed for Polyglot, this post on stackoverflow helped me.
Polyglot tries to automatically detect the language in which a text is written and apply the correct model (i.e., for PoS-tagging, NER, etc.). But, due to foreign names, sometimes it detects the language as being English or other rather than Portuguese, but you can force the language of a text and override the language detection mechanism
II) I used RegexpParser from NLTK to encode ReVerb’s regular expression adapted to Portuguese. The PoS-tags given by Polyglot follow the Universal Part of Speech tags set, 17 unique tags.
verb = "<ADV>*<AUX>*<VERB><PART>*<ADV>*"
word = "<NOUN|ADJ|ADV|DET|ADP>"
preposition = "<ADP|ADJ>"
rel_pattern = "( %s (%s* (%s)+ )? )+ " % (verb, word, preposition)
grammar_long = '''REL_PHRASE: {\\%s}''' % rel_pattern
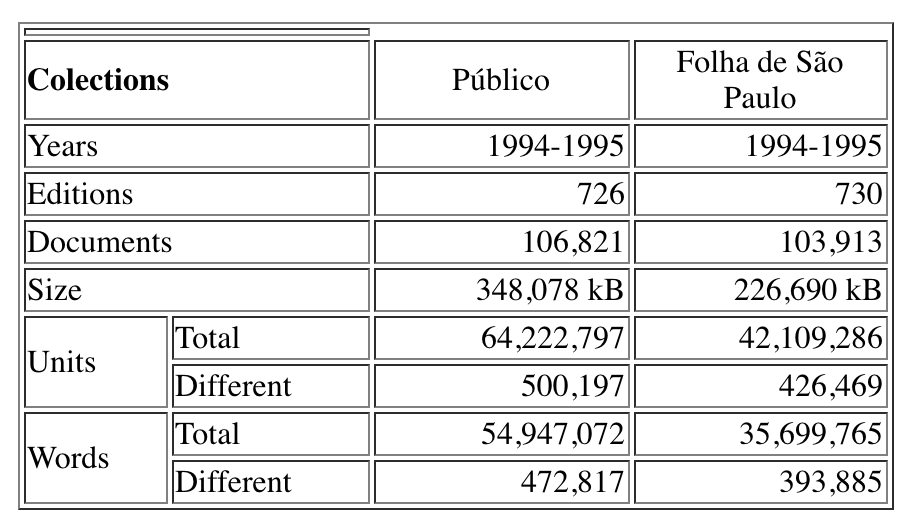
III) CHAVE, is a collection of Portuguese news articles, available free of charge for research proposes distributed by Linguateca.
You just need to give an email address to receive the credentials allowing you to download the collection. It contains all the complete published editions for the years of 1994 and 1995 for two popular newspapers, PUBLICO from Portugal and Folha de São Paulo from Brazil. The figure below is a statistical description of the dataset.
I used Polyglot to identify named entities and perform part-of-speech tagging, then I looked for ReVerb patterns between every pair of named entities which were no more than 8 tokens apart. I extracted triples from PUBLICO news articles from the following categories:
['Nacional', 'Mundo', 'Economia', 'Sociedade', 'Cultura']
This took around 2 hours to run on a Mac Book Pro and extracted around 70 000 unique relational triples. I then started to explore the extracted triples by simply using grep, to find triples referring to specific entities.
There are interesting facts in the semantics triples, mostly, of course, related to events in 1994 and 1995, for instance:
When Madredeus start to gain international fame and tour outside of Portugal:
Teresa Salgueiro cantar composições do Pedro Ayres Magalhães
Madredeus esgota salas em Gent
Madredeus vendem tanto como Paul McCartney
Madredeus gravar em Inglaterra
Madredeus recusam convite do PSD
Teresa Salgueiro frequentou aulas de canto com Cortês Medina
When the East-Timor conflict gained larger and political proportions:
Bill Clinton falou no problema dos direitos humanos em Timor-Leste
Bill Clinton levante a questão de Timor-Leste
Bill Clinton também não deixará de mencionar a questão de Timor
Governo da Indonésia não poupa ataques Portugal
Coliseu do Porto haverá um espectáculo de solidariedade com Timor
Danielle Mitterrand participar numa conferência sobre Timor-Leste
Durão Barroso lança apelo por Timor
Galvão de Melo não poupou elogios à presença indonésia em Timor
Governo russo reconheceu Timor-Leste
Indonésia explora petróleo do Timor
Indonésia ocupou o território de Timor
Indonésia acusa Portugal
The big rock concerts at the Alvalade stadium:
Alvalade montar o espectáculo da banda de David Gilmour
Alvalade ouvir a música dos Pink Floyd
Jagger tocou em Alvalade
Bryan Adams arrasa Alvalade
Damásio prometeu roubar os concertos ao seu rival de Alvalade
Pink Floyd esgotam Alvalade
Pink Floyd tocam Alvalade
Rod Stewart dá um concerto em Lisboa
Van Halen fazerem a primeira parte do concerto dos Bon Jovi
The typical messages of accusation and support in politics:
António Guterres responde às críticas de Luís Filipe Menezes
Manuel Monteiro acusou ontem António Guterres
Narciso Miranda dedicou a vitória a António Guterres
PCP não poupou críticas a Guterres
PS teceu fortes críticas ao PSD
PSD criticou o governo de Guterres
Sampaio elogiando a capacidade de Guterres
Sampaio entra para o longo abraço a Guterres
And the investments, buys and sells of shares in economics:
António Champalimaud aumentar o capital da Mundial Confiança
Sonae Investimentos lançou sobre as acções da Interlog SGPS
British Aerospace queria vender a totalidade das acções da Rover
Carlsberg entrou no capital da Unicer
Continente lançou sobre a totalidade do capital da Modelo
Microsoft adquiriu todas as acções da Altamira
Portucel não acompanhará o aumento de capital da Inapa
Renault conduziu a uma forte subida das acções da Volvo
Santander entra efectivamente no capital do BCI
But there is also uninformative extractions, which occur mainly due to two problems:
- NER component of Polyglot
- ReVerb limitations - which are also pointed out in the original paper
Named-Entity Recognition Errors
One of the problems with the extraction has to do with Polyglot failing to correctly identify the named entities. Polyglot often detects wrong named-entities, for instance:
! I-ORG
' I-PER
) I-ORG
. . ) ? I-PER
. . . ' I-ORG
. . . . I-PER
. . . . . . . . . . . I-PER
17.3.95 I-PER
22.06.94 I-LOC
2C I-ORG
4.10.1952 I-LOC
4AD I-ORG
52n Street I-ORG
72nd West I-ORG
? . . . I-PER
Actualidade I-ORG
or sometimes the named entities are incomplete, for instance, given the phrase:
“O Fundo BPI América, gerido pela Douro Fundos, grupo Banco Português de Investimento, …“
The following triple is extracted, with the incomplete entity “Douro” tagged as LOCATION
BPI América gerido pela Douro
Shallow Analysis of the Sentence
ReVerb operates only at a shallow sentence level, it does not take into consideration syntactic dependencies among words or groups of words, as a consequence it only extracts binary relationships. Given this sentence:
“Fontes diplomáticas citadas pela AFP referiram que Washington sempre encarou com desagrado qualquer anúncio de redução de efectivos da ONU na Bósnia antes da formação de uma nova força multinacional”
the following triple is extracted:
AFP referiram Washington
and “Washington” wrongly as tagged as a PERSON.
This is a complex sentence, and there is not a simple binary relationship that expresses all the information in the sentence.
Future Work
This was a quick experiment on how to perform open information extraction in Portuguese using only open and out-of-the-box tools. Two things that need to be improved are:
- Go beyond part-of-speech tags, i.e., syntactic dependencies
- Improve the named-entity recognition
It’s easy to solve this in English, but in Portuguese, it’s more complicated. For morphological and syntactic information for Portuguese, there is SyntaxNet, but I still have to find a way to make it work in batch or inside my own Python code.
For Named-Entity Recognition, as far as I know, apart from Polyglot, there is no other library, ready to use out of the box. There are datasets available, which can be transformed and used as training data. I will try to address this issue in the future, and hopefully make a post about it.
The full code and the extracted triples are available on my GitHub:
https://github.com/davidsbatista/information-extraction-PT
Related posts
information-extraction relationship-extraction pos-tags NLTK 