Retrieval methods in RAG - Haystack
Retrieval Augmented Generation (RAG) is a model architecture for tasks requiring information retrieval from large corpora combined with generative models to fulfill a user information need. It’s typically used for question-answering, fact-checking, summarization, and information discovery.
The RAG process consists of indexing, which converts textual data into searchable formats; retrieval, which selects relevant documents for a query using different methods; and augmentation, which feeds retrieved information and the user’s query into a Large Language Model (LLM) via a prompt for output generation.
Typically, one has little control over the augmentation step besides what’s provided to the LLM via the prompt and a few parameters, like the maximum length of the generated text or the temperature of the sampling process. On the other hand, the indexing and retrieval steps are more flexible and can be customized to the specific needs of the task or the data.
In this blog post I will different retrieval techniques, some rooted in the area of classic information retrieval others, which were proposed recently, and based on LLMs.
The code for all the experiments in this blog post can be found here:
From Classic Information Systems to RAG
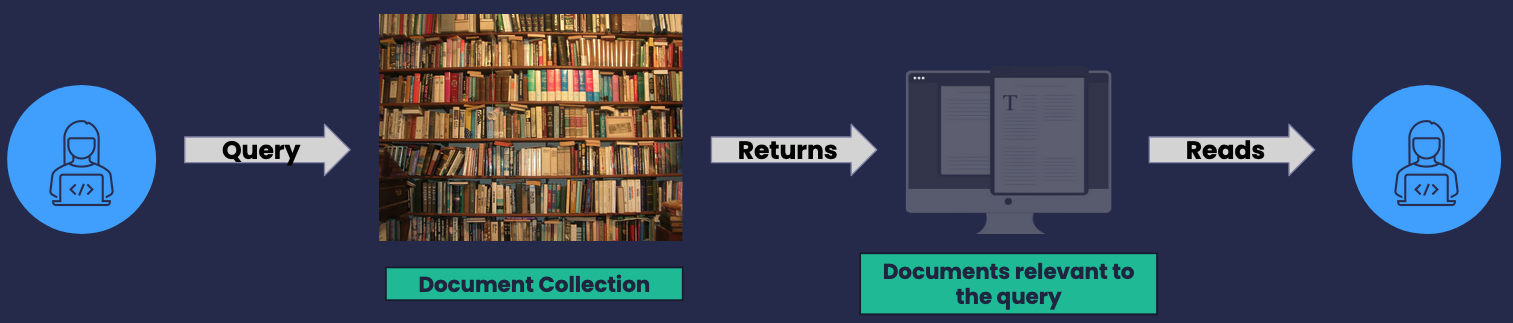
- Classical Information Retrieval system returns a list of documents or snippets
- Requiring users to read through multiple results to find the information they need
- A complex or nuanced query requires a deeper understanding of the context and relationships between different pieces of information
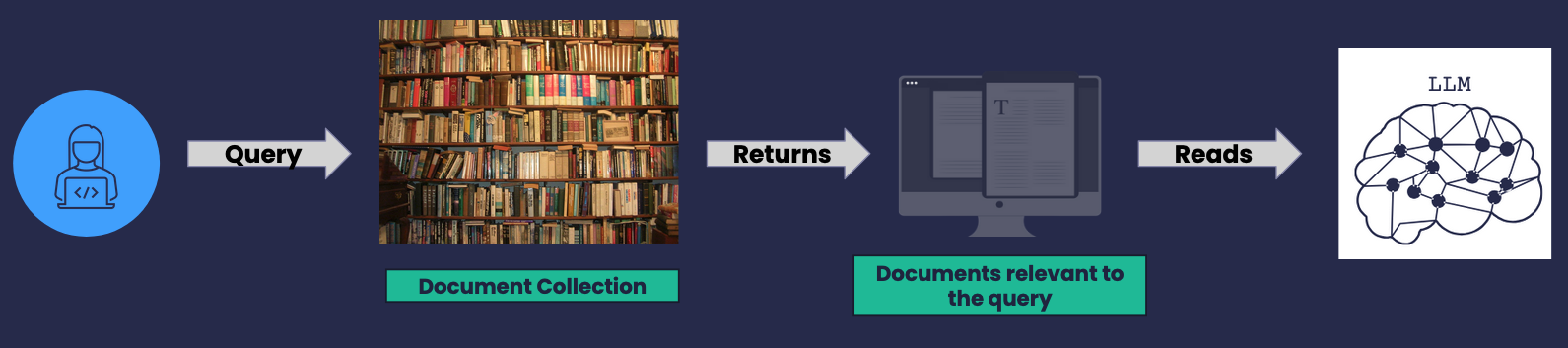
- What if, instead the user sifting through the results, we build a prompt composed by retrieved snippets together with the query and feed it to an LLM?
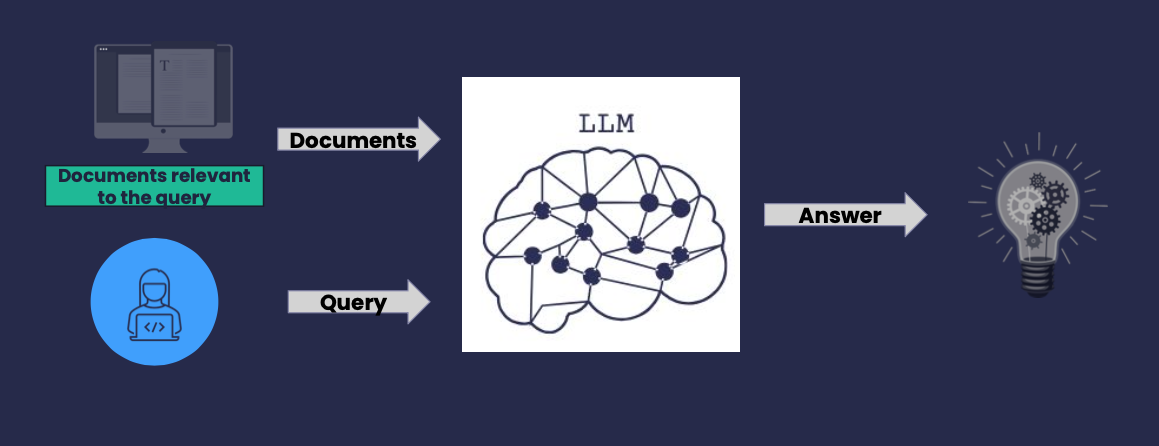
- The idea is to pass the results together with the question query to the LLM, asking it to compose an answer based on the question query and the results.
Baseline Retrieval
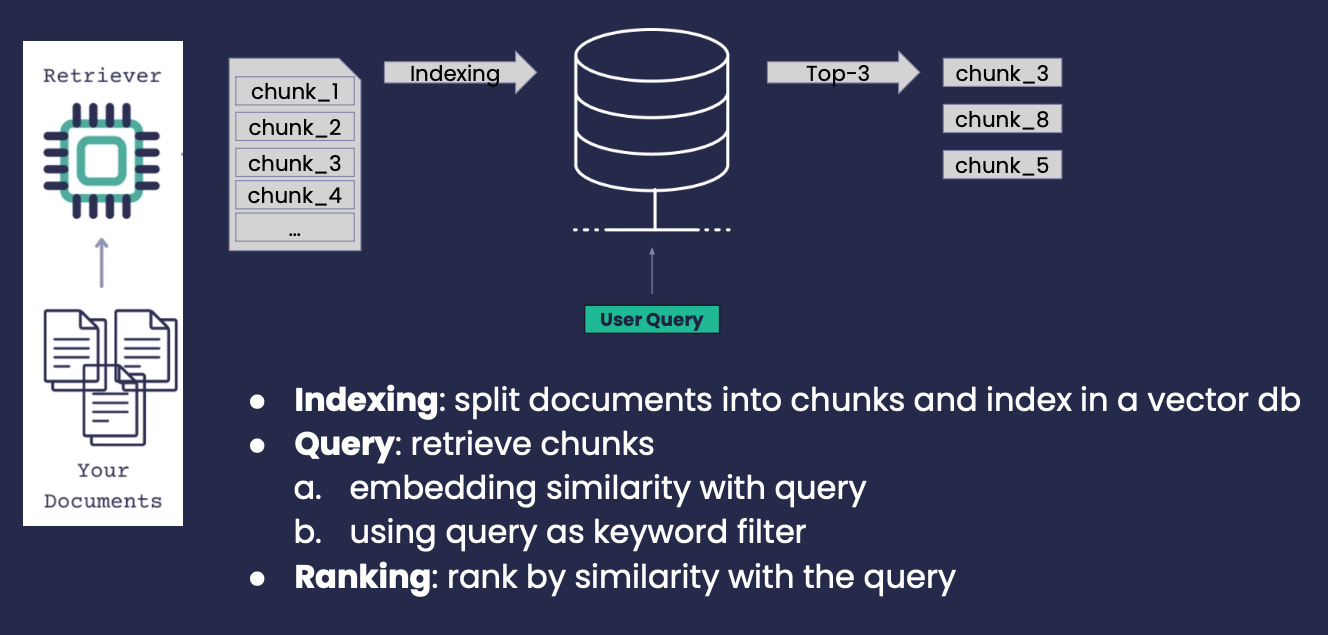
● Indexing: split documents into chunks and index them in a vector db
● Query: retrieve chunks
-
embedding similarity with query
-
using query as keyword filter
● Ranking: rank by similarity with the query
Classical Techniques
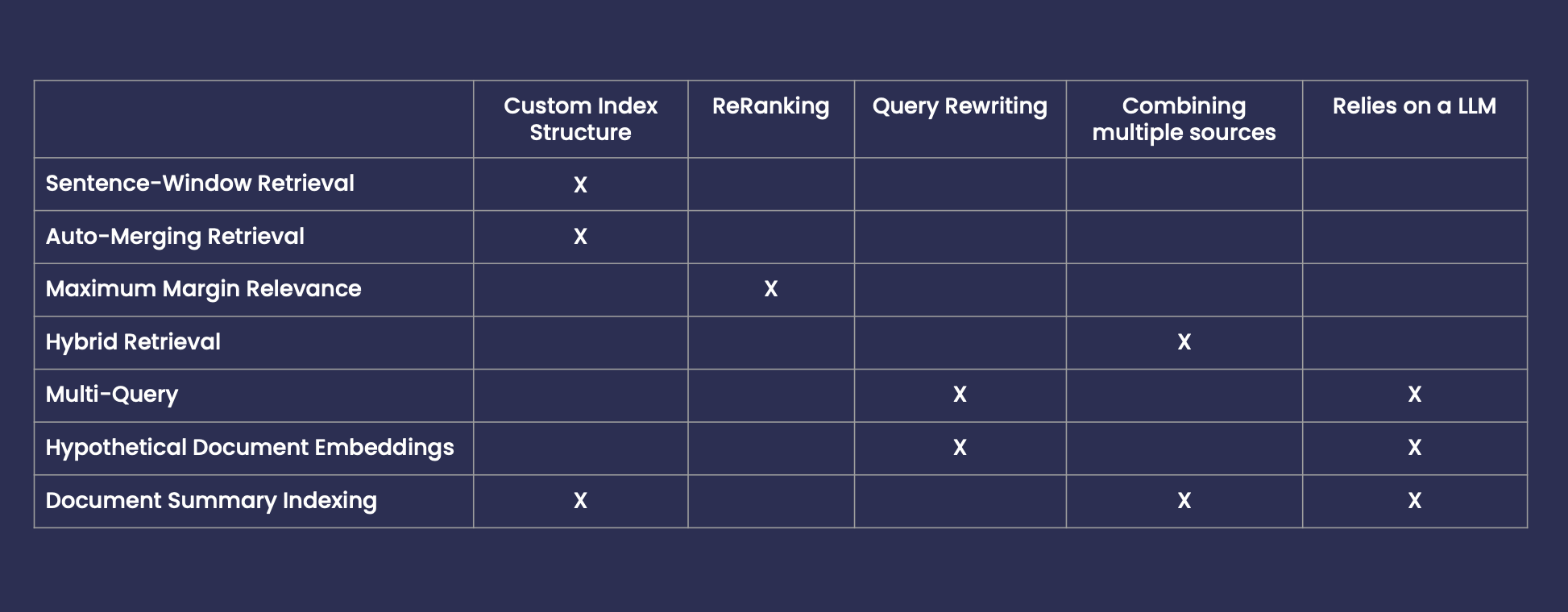
- Sentence-Window-Retrieval
- Auto-Merging Retrieval
- Maximum Marginal Relevance
- Hybrid Retrieval
Sentence-Window Retrieval
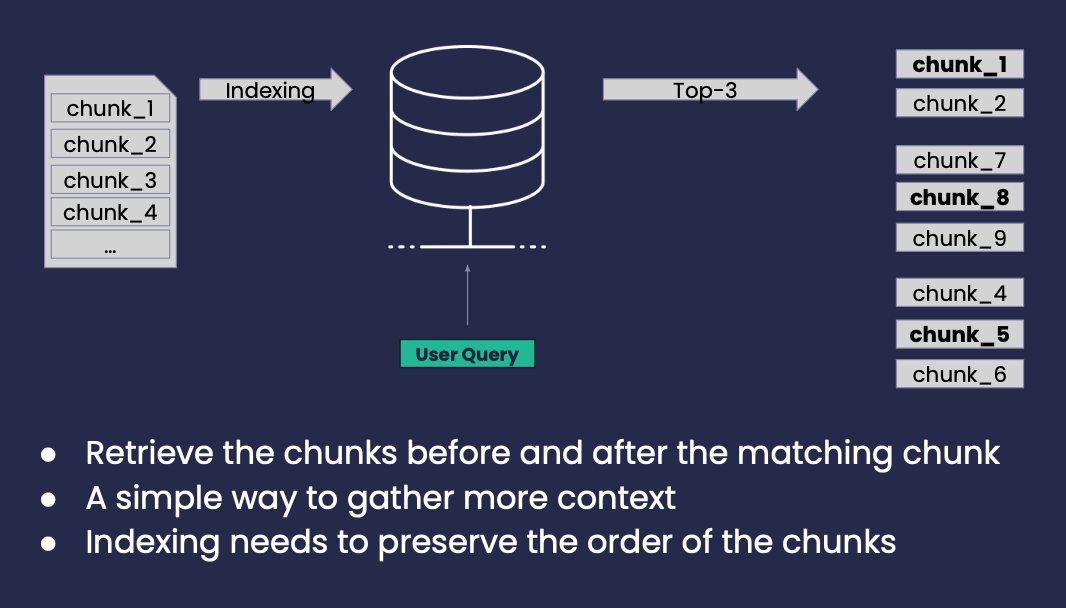
Auto-Merging Retrieval
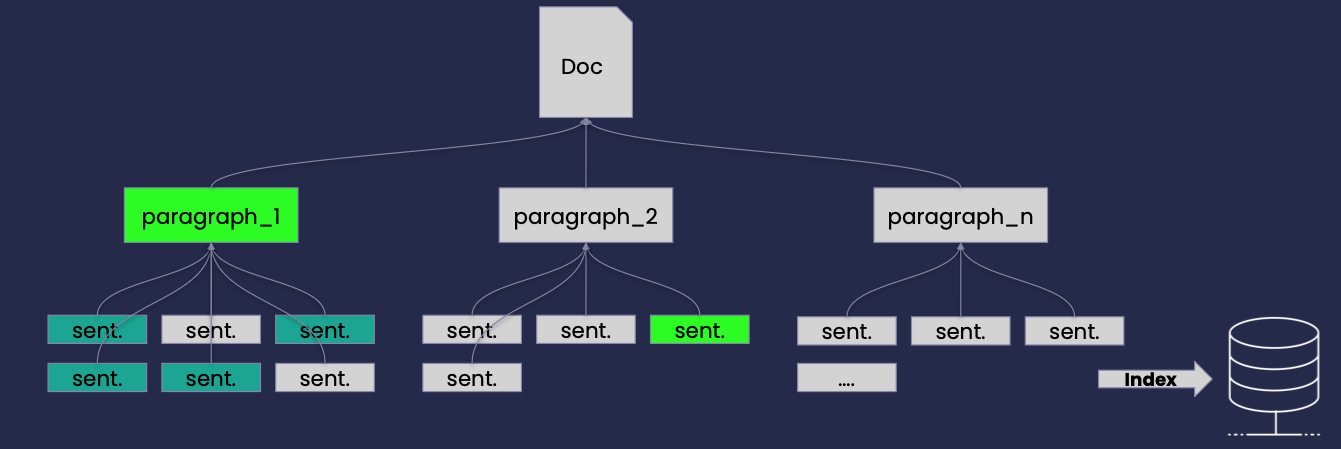
Index
-
Transform documents into an Hierarchical Tree structure (e.g. full text -> paragraphs -> sentences)
-
Leaf chunks/sentences are index and used for retrieval
Retrieval
-
Set a threshold of 0.5, if the number of matches is above the set threshold return the parent instead of individual children.
-
The paragraph_1 is returned, instead of 4 sentences
-
Plus, the one sentence from paragraph_2
-
A whole paragraph might be more informative than individual chunks
Maximum Marginal Relevance (MMR)
● Classical retrieval ranks the retrieved documents by relevance similarity to the user query
● What about scenarios with a high number of relevant documents, but also highly redundant or containing partially or fully duplicative information?
● We need to consider how novel is a document compared to the already retrieved docs
- Maximum Marginal Relevance scores each retrieved document considering the already retrieved documents and the user query, it’s essentially a re-ranking technique, where the first document is the most similar to the query and the following documents are the most relevant to the query and most dissimilar from the already retrieved documents.
It uses the following formula to score each document:
\[MMR = \arg \max_{d_i \in D \setminus R} \left[ \lambda \cdot \text{Sim}_1(d_i, q) - (1 - \lambda) \cdot \max_{d_j \in R} \text{Sim}_2(d_i, d_j) \right]\]\(D\) - is the set of all candidate documents
\(R\) - is the set of already selected documents
\(q\) - is the query
\(\text{Sim}_1\) - is the similarity function between a document and the query
\(\text{Sim}_2\) - is the similarity function between two documents
\(d_i\) and \(d_j\) - are documents in \(D\) and \(R\) respectively
\(\lambda\) - is a parameter that controls the trade-off between relevance and diversity
The formula is applied to each of the retrieved documents:
-
Similarity between the candidate document and the query
-
Find maximum similarity between a candidate document and any previously selected document.
-
Maximize the similarity to already selected documents and then subtracting it - penalize documents that are too similar to what’s already been selected.
-
λ balances between these two terms
Hybrid Retrieval
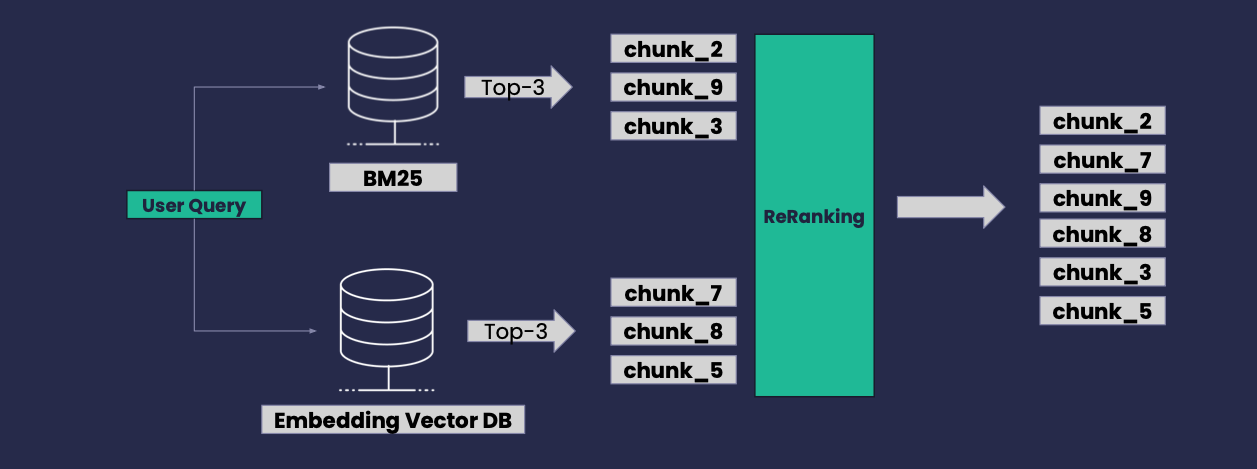
● Combines multiple search techniques
● (BM25) and semantic-based (embedding vector) keyword-based (BM25) and semantic-based (embedding vector)
● Rank-merge results
LLLM-based Techniques
- Multi-Query
- Hypothetical Document Embeddings - HyDE
- Document Summary Indexing
Multi-Query
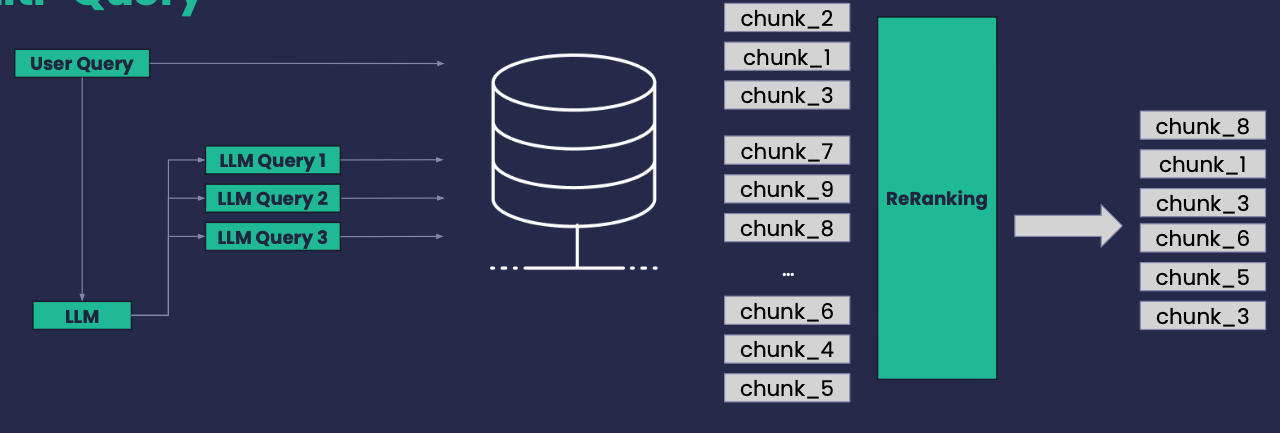
● Expand a user query, based on a LLM, into n similar queries reflecting the original intent
● ..or break-down a complex query into individual questions
● Each new query is used for an individual retrieval processes
● Re-ranking process over all retrieved chunks
Hypothetical Document Embeddings - HyDE
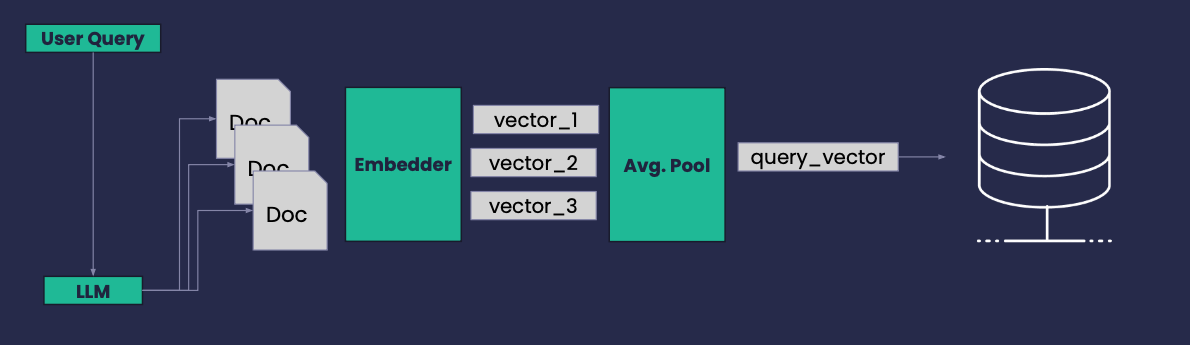
● Given a user query, use a LLM to generate n “hypothetical” (short) documents whose content would ideally answer the query
● Each of the n documents is embedded into a vector
● You perform an average pooling generating a new query embedding used to search for similar documents instead of the original query
Document Summary Indexing
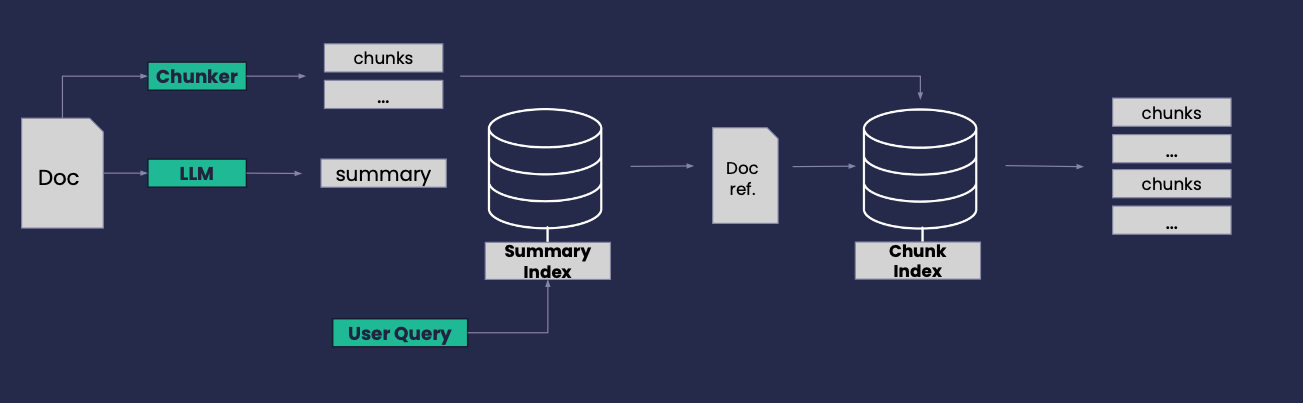
Indexing
-
Summary Index: generate a summary for each document with an LLM
-
Chunk Index: plit each document up into chunks
Retrieval
-
Use the Summary Index to retrieve top-k relevant documents to the query
-
Summary Index: generate a summary for each document with an LLM
-
Chunk Index: split each document up into chunks
-
Using the document(s) reference retrieve the most relevant chunks
Summary
Comparative Experiment
“ARAGOG: Advanced RAG Output Grading” M Eibich, S Nagpal, A Fred-Ojala arXiv preprint, 2024
Dataset:
-
ArXiv preprints covering topics around Transformers and LLMs
-
13 PDF papers (https://huggingface.co/datasets/jamescalam/ai-arxiv)
-
107 questions and answers generated with the assistance of an LLM
-
All questions and answers were manually validated and corrected
Experiment:
-
Run the questions over each retrieval technique
-
Compare ground-truth answer with generated answer
-
Semantic Answer Similarity: cos sim embeddings of both answers
| Retrieval Method | Semantic Answer Similarity | Specific Parameters |
|---|---|---|
| Sentence-Window Retrieval | 0.688 | window=3 |
| Auto-Merging Retrieval | 0.619 | threshold=0.5, block_sizes={10, 5} |
| Maximum Margin Relevance | 0.607 | lambda_threshold=0.5 |
| Hybrid Retrieval | 0.701 | join_mode=”concatenate” |
| Multi-Query | 0.692 | n_variations=3 |
| HyDE | 0.642 | nr_completions=3 |
| Document Summary Indexing | 0.731 | - |
Takeaways
-
Build a dataset for your use case - 50~100 annotated questions
-
Start with the simple RAG approach and set it as your baseline
-
Start by exploring “cheap” and simple techniques
-
Sentence-Window Retriever and Hybrid Retrieval give good results and no need for complexing indexing or an LLM
-
If none of these produces satisfying results then, explore indexing/retrieval methods based on LLMs
References
-
“ARAGOG: Advanced RAG Output Grading” M Eibich, S Nagpal, A Fred-Ojala arXiv preprint, 2024
-
“Advanced RAG: Query Decomposition & Reasoning” ****- Haystack Blog, 2024
-
“A New Document Summary Index for LLM-powered QA Systems”, Jerry Liu 2023
Code
The code for all the experiments can be found here
haystack information-retrieval RAG 