PyData Berlin 2017
The PyData Berlin conference took place at the first weekend of July, at the HTW. Full 3 days of many interesting subjects including Natural Language Processing, Machine Learning, Data Visualisation, etc. I was happy to have my talk proposal accepted and had the opportunity to present work done during my PhD on Semantic Relationship extraction.

Evaluating Topic Models
Matti Lyra gave an interesting talk on how to evaluate unsupervised models, mostly focused on how to evaluate topic models generated from LDA. He went through the proposed evaluation methodologies and described the pros and cons of each one of them. Slides are available here

AI-assisted creativity
Roelof Pieters from creative.ai presented a talk about AI-assisted creativity, mainly focusing on how generative models based on neural networks can be used to generate text, audio, speech, and images. The talk was focused on how to use these models as an augmentation tool and not an automation tool. It also presented a good history and a timeline for machine learning-assisted art generation.

Developments in Test-Driven Data Analysis
Nick Radcliffe presented something which is new to me and grab my attention: Test-driven data analysis (TDDA), inspired by test-driven development. The TDDA library allows keeping your data clean and automatically discover constraints and validation rules. TDDA web site and GitHub project page. Slides are available here.

What does it all mean? - Compositional distributional semantics for modelling natural language
Thomas Kober gave us a very good overview of techniques to compose word embeddings in a way that captures the meaning of longer units of text. In other words, how to combine single-word embeddings by applying some kind of function in order to represent sentences or paragraphs. Slides are available here.

Machine Learning to moderate ads in real-world classified’s business
Vaibhav Singh and Jaroslaw Szymczak shared their experiences and learnings in building machine learning models to act as human moderators for ads in an online marketplace, OLX. They share some good tips on what to focus when you want to deploy machine learning models in production. Slides are available here.

Find the text similarity you need with the next generation of word embeddings in Gensim
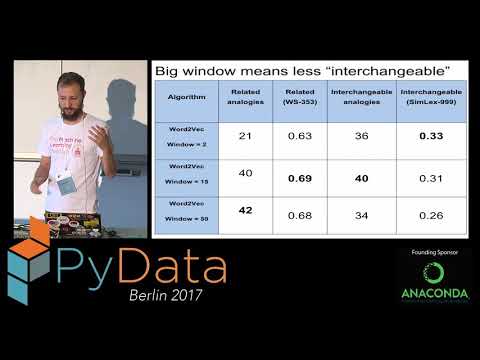
Lev Konstantinovskiy from RaRe Technologies gave an overview of the different methods to generate embeddings: Word2Vec, FastText, WordRank, GloVe and some of the wrappings existent in gensim.
On Bandits, and, Bayes swipes: gamification of search
Stefan Otte talked about a topic which I find very interesting but somehow does not get much attention, Active Learning (wiki), Active Learning Literature Survey. He did an introduction to the topic, briefly going through the different active learning strategies, and connected it to a multi-armed bandit setting, in a product ranking scenario. Slides are available here.

Semi-Supervised Bootstrapping of Relationship Extractors with Distributional Semantics
And finally, a link to my talk, where I showed the results of a bootstrapping system for relationship extraction based on word embeddings. Slides are available here.

PyData conference 